





Learning without examples (zero-shot learning - ZSL) [5] consists in recognising objects or other visual classes with a model that has not used any examples of these classes during its learning phase. To compensate for this lack of information, each class is associated with a semantic prototype that reflect the characteristics of this class. During the learning phase, the model learns to match the visual information with these intermediate characteristics. Thus, during the test phase the images of the unseen classes can be recognised by the model.
This formalism, introduced at the end of the 2000s, has seen renewed interest in recent years and the proposed models have gained in performance. This has also been accompanied by a more precise definition of the task, in order to better correspond to real use cases. The work of the CEA List in this field is in line with this trend and we have proposed several contributions to get closer to a use of ZSL on real cases.

The generalised version of the task (generalized zero-shot learning - GZSL) allows, during the test phase, to recognise both unseen classes as in classic ZSL, but also classes seen during training. In such a context, classic ZSL models are usualy strongly biased towards the recognition of classes already seen.
We proposed a method to automatically select the hyper-parameters of a classical ZSL method in order to improve its performance in the GZSL case. In practice, the performance is improved by 48% on CUB and 102% on AWA2 [1].
We have also identified several implicit assumptions in ZSL approaches that penalise their performance. We proposed a series of methods to correct them [2]. Again, this leads to a significant gain in recognition [2].
Semantic prototypes traditionally consist of a list of (binary) attributes describing each class, such as "has a beak" or "has fur". When the number of classes becomes large (several hundred), and the number of attributes is large as well, it becomes tedious to create such prototypes manually. It is then common to use prelearned lexical extensions (word embeddings) calculated on the name of the classes. This possible scaling up unfortunately leads to a drastic decrease in perfromances.
We have proposed to automatically build semantic prototypes from richer information [3] or by using large corpora better adapted to the description of visual characteristics [4]. Thus, we obtained the best performances reported in 2020 on ILSVRC in ZSL.

[1] Y. Le Cacheux, H. Le Borgne, M. Crucianu (2019) From Classical to Generalized Zero-Shot Learning: a Simple Adaptation Process, 25th International Conference on MultiMedia Modeling (MMM), Thessaloniki, Greece, January 8-11
[2] Y. Le Cacheux, H. Le Borgne and M. Crucianu (2019) Modeling Inter and Intra-Class Relations in the Triplet Loss for Zero-Shot Learning. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Seoul, Korea, Oct. 27 - Nov. 2
[3] Y. Le Cacheux, H. Le Borgne, M. Crucianu (2020) Webly Supervised Semantic Embeddings for Large Scale Zero-Shot Learning Task-CV workshop@ECCV, Online, 23-28 August 2020
[4] Y. Le Cacheux, A. Popescu, H. Le Borgne (2020) Using Sentences as Semantic Representations in Large Scale Zero-Shot Learning, Asian Conference on Coputer Vision (ACCV), Kyoto, 2020
[5] Y Le Cacheux, H Le Borgne, M Crucianu (2021) Zero-shot Learning with Deep Neural Networks for Object Recognition, In : J. Benois Pineau and A. Zemmari (Eds.) Multi-faceted Deep Learning. Springer, 2021. Chap. 6, p. 273-288.
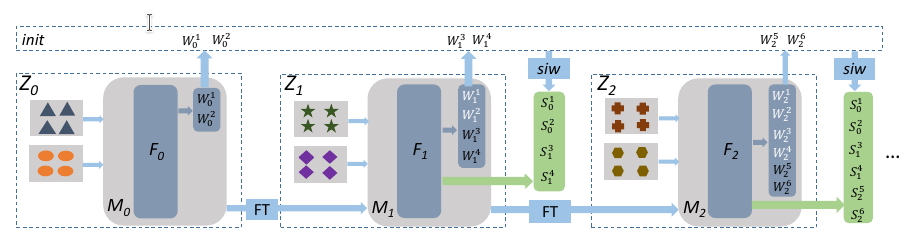
Standard deep learning models work very well under the assumption that training data are available at all times. However, this hypothesis in often not verified in practice. For instance, past data might become unavailable due to privacy reasons, as it is the case when training models on medical data from multiple sites, or because the available memory is limited, as it is the case for embedded systems. In such cases, the artificial agent needs to learn from dynamic data in an incremental (or continual) fashion. It has to integrate new knowledge with limited or no access to past data. This leads to a catastrophic forgetting of previously learned information when new knowledge is integrated. Since 2018, CEA LIST proposed class incremental learning algorithms which are adapted to both scenarios.
When a bounded memory of he past is available, the proposed works [2,3,4] have shown that the use of knowledge distillation, a de facto standard in the community, is useless if not harming for overall performance at scale. Here, incremental learning can be modeled using methods inspired by imbalanced learning [4,6], which are simpler than competing methods and least as accurate.
Incremental learning is even more difficult in absence of past memory.


A transfer learning based approach [1] is very efficient if an initial model can be trained with enough data and if the new classes are not radically different from the initial ones [6]. If this happens, deep model updates are needed when integrating new classes and this is usually done using fine tuning with knowledge distillation. CEA LIST has very recently proposed a different approach [5] which exploits initial classifier for each past class and applies a normalization in order to ensure prediction fairness between new and past classes. This method clearly outperforms existing ones and is also much simpler.
[1] E. Belouadah A. Popescu "DeeSIL: Deep-Shallow Incremental Learning", Proceeding of ECCV Workshops 2018.
[2] E. Belouadah A. Popescu "Il2m: Class incremental learning with dual memory", Proceeding of ICCV 2019.
[3] E. Belouadah A. Popescu "ScaIL: Classifier Weights Scaling for Class Incremental Learning", Proceeding of WACV 2020.
[4] E. Belouadah A. Popescu, I. Kanellos "Initial Classifier Weights Replay for Memoryless Class Incremental Learning", Proceeding of WACV 2020.
[5] E. Belouadah, A. Popescu, U. Aggarwal, L. Saci "Active Class Incremental Learning for Imbalanced Datasets", Proceeding of ECCV Workshops 2020.
[6] E. Belouadah A. Popescu, I. Kanellos "Initial Classifier Weights Replay for Memoryless Class Incremental Learning", Proceeding of BMVC 2020.
[7] E. Belouadah A. Popescu, I. Kanellos “A Comprehensive Study of Class Incremental Learning Algorithms for Visual Tasks”, Neural Networks 135, 38-54
[8] H Slim, E Belouadah, A Popescu, D Onchis, Dataset Knowledge Transfer for Class-Incremental Learning Without Memory, WACV 2022
Deep learning models are powerful but require a large amount of precisely annotated data to estimate their parameters. However, in practice, it is common to have little annotated data available, and their production is often a time-consuming and costly process. As well, it may require expertise that is scarce for some specialised fields. Moreover, once the model is learned, it is usually frozen and evolving it often requires relearning it entirely, which is again a long and costly process.
Since 2014, the CEA List has implemented the Semfeat technology, which makes it possible to recognise tens of thousands of classes, to add and remove classes at will and, above all, to carry out this annotation quickly and efficiently. In addition, it also provides a particularly effective image description for large-scale visual content searches. This academic research is gradually being integrated into an industrialised brick that can be deployed in a variety of information systems.
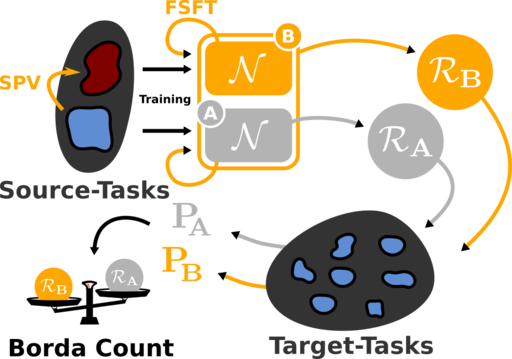
The principle of transfer is to describe the images using a fixed core model and then to learn a light model for each visual concept of interest [1]. Each concept is learned from a limited number of annotated examples, which can be automatically collected from the web and then ``cleaned up'' to avoid manual work [2].


A small number of visual concepts can be selected to produce a "hollow" representation of the image, which is particularly effective in a context of visual content research [1, 3, 4]. We have also developed an indexing technology linked to this property that allows us to find an image with a complexity that is almost independent of the size of the base [5, 5a].
As images are described according to semantic concepts, it is possible to merge these signatures with representations of textual content, further improving classification or content-based search capabilities, and making it possible to describe multimedia documents with both visual and textual content [6].


The core network is itself learned on a source learning basis, and the induced descriptions are less effective when the problem of target interest is very different from the source problem. We have developed methods to make the core network more universal, i.e. to make it perform on a larger number of target problems. The advantage of our approach is that it is very economical in terms of additional manual labour, typically reducing it by a factor of 1000 compared to previous approaches [7, 8].
[1] A. Gînsca, A. Popescu, H. Le Borgne, N. Ballas, D. P. Vo, I. Kanellos, Large-scale Image Mining with Flickr Groups, 21st International Conference on Multimedia Modelling (MMM2015), 5-7 january 2015, Sydney, Australia, 2015.
This paper receives the best paper award at MMM 2015
[2] P. Vo, A. Ginsca, H. Le Borgne and A. Popescu, Harnessing Noisy Web Images for Deep Representation, Computer Vision and Image Understanding, Volume 164, November 2017, Pages 68-81
[3] Y. Tamaazousti, H. Le Borgne and C. Hudelot, Diverse Concept-Level Features for Multi-Object Classification, Proc. ACM International Conference on Multimedia Retrieval (ICMR 2016), New York, USA, June 2016
[4] Y. Tamaazousti, H. Le Borgne and A. Popescu, Constrained Local Enhancement of Semantic Features by Content-Based Sparsity, Proc. ACM International Conference on Multimedia Retrieval (ICMR 2016), New York, USA, June 2016
[5] A. Popescu, A. Gînsca, H. Le Borgne, Scale-Free Content Based Image Retrieval (or Nearly So), The IEEE International Conference on Computer Vision Workshop (ICCVW) on Web-Scale Vision and Social Media, 2017, pp. 280-288
[5a] Method and system for searching for similar images that is nearly independent of the scale of the collection of images. US Patent App. 15/763,347
[6] Y. Tamaazousti, H. Le Borgne, A. Popescu, E. Gadeski, A. Gînsca, and C. Hudelot, Vision-language integration using constrained local semantic features, Computer Vision and Image Understanding, vol. 163, pp 41-57, october 2017
[7] Y. Tamaazousti, H. Le Borgne and C. Hudelot, MuCaLe-Net: Multi Categorical-Level Networks to Generate More Discriminating Features, Computer Vision and Pattern Recognition (CVPR 2017), Hawaii, USA, July 2017
[8] Y. Tamaazousti, H. Le Borgne, C. Hudelot, M.E.A Seddik, M. Tamaazousti (2019) Learning More Universal Representations for Transfer-Learning, IEEE T. Pattern Analysis and Machine Intelligence (PAMI) (pre-print 2019)
The work on information synthesis falls within the framework of multi-document summary by extraction by integrating in their most recent version a dimension of temporal updating exploiting, within the same framework of linear integer optimisation, the semantic similarity of sentences based on lexical plunges [1] and the discursive structure of texts according to the paradigm of rhetorical structure theory (RST).
[1] Maâli Mnasri, Gaël de Chalendar, and Olivier Ferret. Taking into account inter-sentence similarity for update summarization. In Eighth International Joint Conference on Natural Language Processing (IJCNLP 2017), short paper session, pages 204–209, Taipei, Taiwan, November 2017. Asian Federation of Natural Language Processing.
Entity disambiguation consists in automatically linking references to entities identified in a text and entities present in a knowledge base. The general approach consists in producing, for a given mention, candidate entities and then selecting the best among them, according to a set of criteria.
We have developed a method based on learning models to discriminate between an entity and entities that are ambiguous to it. A major bottleneck in this context lies in the ability to manage large knowledge bases requiring the learning of dozens of millions of models. We propose three strategies to address this, offering different trade-offs between efficiency and quality of recognition [1].
When the textual context is relatively limited, as is the case in tweets, we take advantage of the visual information to help disambiguation. Our model extracts and then integrates various textual and visual information, in the document and the knowledge base, into a single neural model [2].

As this is a new task, we have developed a method to build, automatically and on demand, an evaluation corpus from Twitter [3]. The knowledge base contains more than 2.5 million entries, each of which is ambiguous by construction. Out of an evaluation corpus containing almost 10^5 documents (one third of them for testing), our model [2] correctly disambiguates 80% of the entities.

[1] H. Daher, R. Besançon, O. Ferret, H. Le Borgne, A-L. Daquo, and Y. Tamaazousti, Supervised Learning of Entity Disambiguation Models by Negative Sample Selection, International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2017), Budapest, Hungary, April 2017
[2] O. Adjali, R. Besançon, O. Ferret, H. Le Borgne and B. Grau (2020) Multimodal Entity Linking for Tweets, 42nd European Conference on Information Retrieval (ECIR): Advances in Information Retrieval
[3] O. Adjali, R. Besançon, O. Ferret, H. Le Borgne and B. Grau, (2020) Building a Multimodal Entity Linking Dataset From Tweets, 12th International Conference on Language Resources and Evaluation (LREC)
Finding an image corresponding to a text allows you, for example, to illustrate the text in a relevant way, or to search for corresponding content. We have explored approaches where text and images are represented in the same vector space. Thus, the comparison of textual and visual contents, or multimodal contents, is significantly facilitated.
Text content naturally conveys a high level semantics, whereas images have representations closer to low-level pixels. Thus, within attached spaces, documents tend to group together more strongly "by modality" than according to their semantics.
We have proposed a new inherently multimodal representation, whereby a document is projected onto several "pivots" representing portions of the quantified joint space [1]. This approach makes it possible to increase the decoupling between modalities within the joined space, so that the approximation of documents reflects their semantics more strongly.
We have also proposed the use of an auxiliary multimodal data set which, by acting as an additional pivot, allows unimodal representations to be completed and made inherently multimodal [2]. In such spaces, document retrieval is also improved.

Even more interestingly, the combination of these approaches makes it possible to envisage a cross-modal classification. Thus, a classifier learned from texts can be directly applied to visual content.
[1] T. Q. N. Tran, H. Le Borgne, M. Crucianu, Aggregating Image and Text Quantized Correlated Components, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2046-2054 , 27th june – 1st july 2016
[2] T. Q. N. Tran, H. Le Borgne, M. Crucianu, Cross-modal Classification by Completing Unimodal Representations, ACM Multimedia 2016 Workshop:Vision and Language Integration Meets Multimedia Fusion, Amsterdam, The Netherlands, October 16, 2016
A large majority of Europeans engage with Online Social Networks (OSNs) and many of them think that they do not have enough control of the data they share and are concerned with the way such data are handled by OSNs. In response to these concerns, the List develop tools that empower users by enhancing their control over the data they distribute or interact with.
Ou initial works were conducted in the context of the USEMP project that directly addressed these problems. It gathered not only expert from multimedia management, but also lawyers and social scientists [1].
As part of USEMP, we introduce a system that performs privacy-aware classification of images. We show that generic privacy models perform badly with real-life datasets in which images are contributed by individuals because they ignore the subjective nature of privacy. Motivated by this, we develop personalized privacy classification models that, utilizing small amounts of user feedback, provide significantly better performance than generic models [2].

[1] A. Popescu et al. (2015) Increasing transparency and privacy for online social network users–USEMP value model, scoring framework and legal, Annual Privacy Forum, 38-59
[2] E. Spyromitros-Xioufis, S. Papadopoulos, A. Popescu, Y. Kompatsiaris (2016) Personalized Privacy-aware Image Classification, Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, pp 71-78, ACM, 2016
[3] VK Nguyen, A Popescu, J Deshayes-Chossart, Unveiling real-life effects of online photo sharing, WACV 2022
