
At CEA LIST, we are conducting research in artificial intelligence applied to computer vision for scene understanding.
Our work focuses on the design of new perception models based on machine learning, including deep learning, for visual recognition in images and videos, analysis of interactions, behaviour analysis of individuals, groups and crowds, visual data analysis and characterization, and smart data annotation.
Research topics
Visual recognition
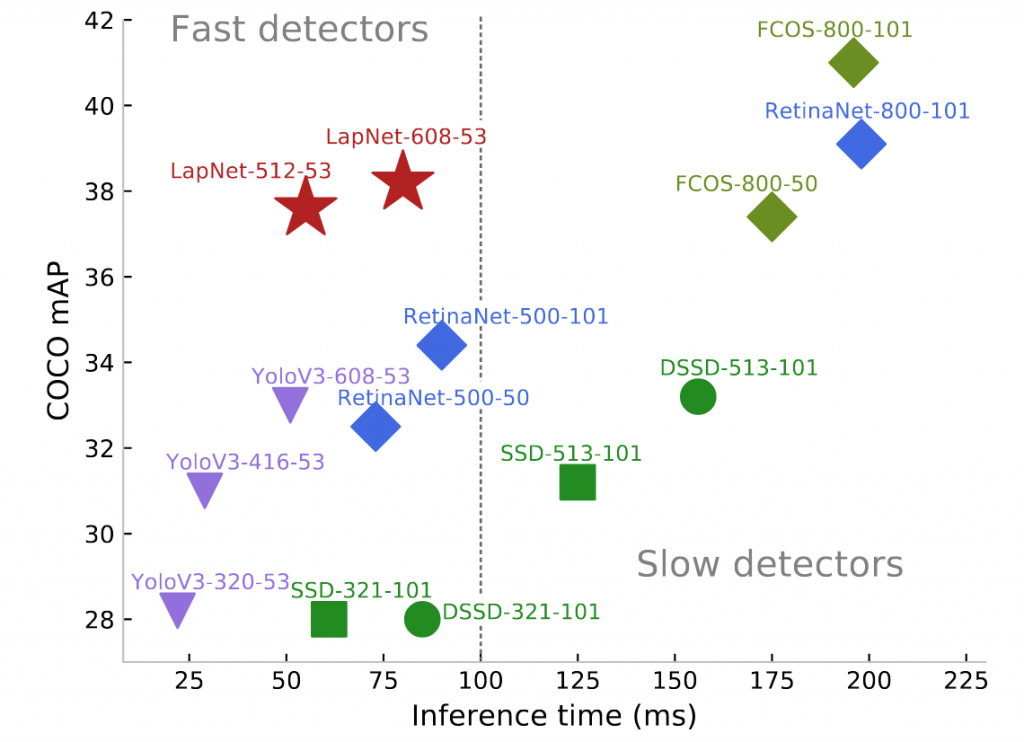
Fast and robust object detection
Lapnet: a single-shot object detector with state-of-the-art performance/inference time trade-off

Fine-grained object recognition
Learning color and edge shared representation from real and synthetic data

Multi-task deep convolutional neural networks for object recognition and semantic segmentation
Deep MANTA (MAny TASk) and Single-Shot Deep MANTA

3D human pose estimation from 2D images
PandaNet: an anchor-based single-shot deep neural network for human detection, 2D and 3D pose estimation

Appearance modeling for person re-identification
End-to-end traning of deep CNN for joint person detection and re-identification

Semantic attribute parsing
Unified framework for semantic attribute and instance segmentation
Behaviour analysis
Real-time Multiple Object Tracking
Track all objects simultaneously in a camera or a camera network by combining object detection and re-id visual appearance features
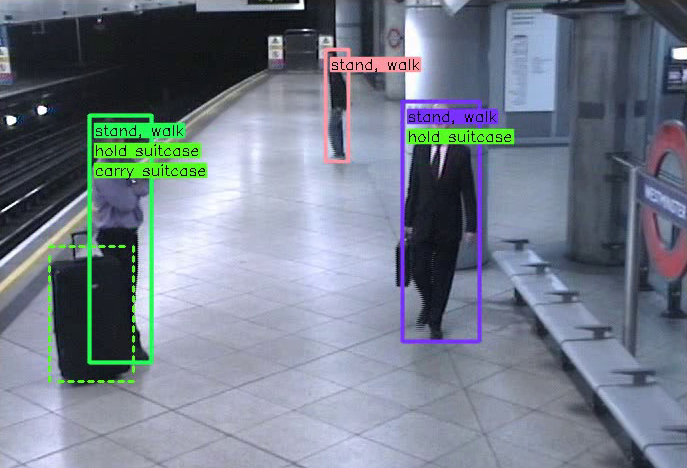
Detecting Interactions
CALIPSO: interaction detection by associating person and objetcs of a scene with a specific interaction label
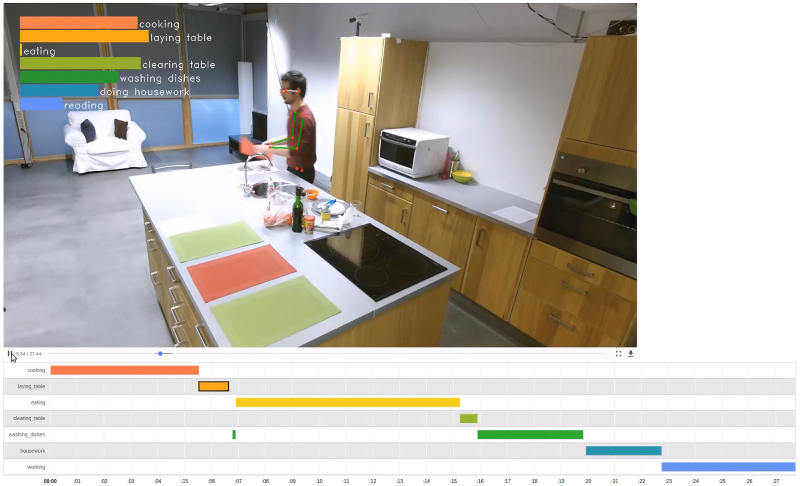
Activity recognition
Recognize everyday activities by analyzing people’s movements

Event detection in videos
RIMOC : a feature to discriminate unstructured motions, application to violent event detection

Crowd behaviour analysis
Crowd-11, a dataset of crowd scenes annotated with 11 classes of behaviour, and CrowdCNN a deep convolutional neural network to discriminate them
Beyond fully supervised learning

Learning with few data
Meta-learning: from theory to practice. Learning to learn with few data from multiple elementary tasks, in order to be able to quickly adapt to the target task, with improved generalization capacity.
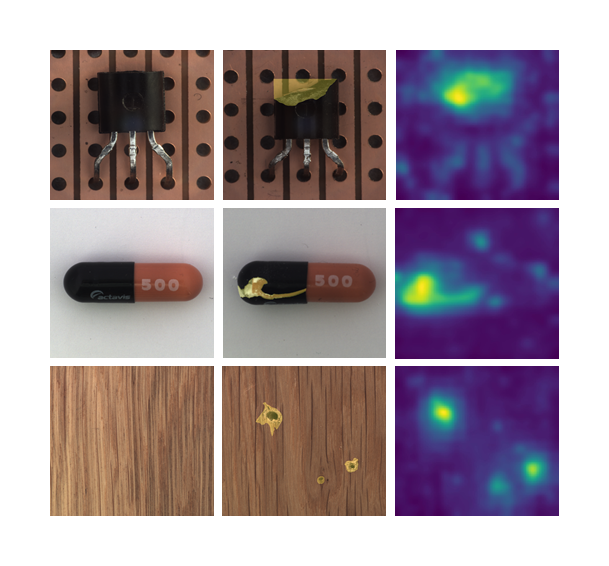
One-class learning for anomaly detection
Patch Distribution Modeling method (PaDiM), a simple yet effective method to detect and localize anomalies in images.
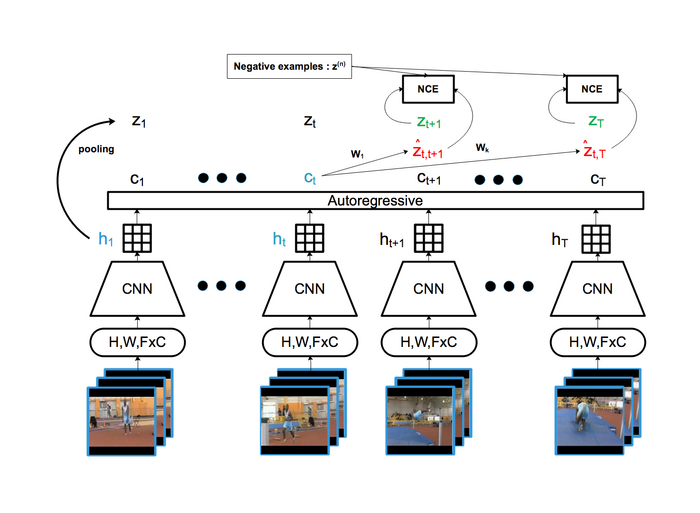
Self-supervised learning of image and video representations
Self-supervised approach based on Contrastive Predictive Coding (CPC) with fully convolutional architecture
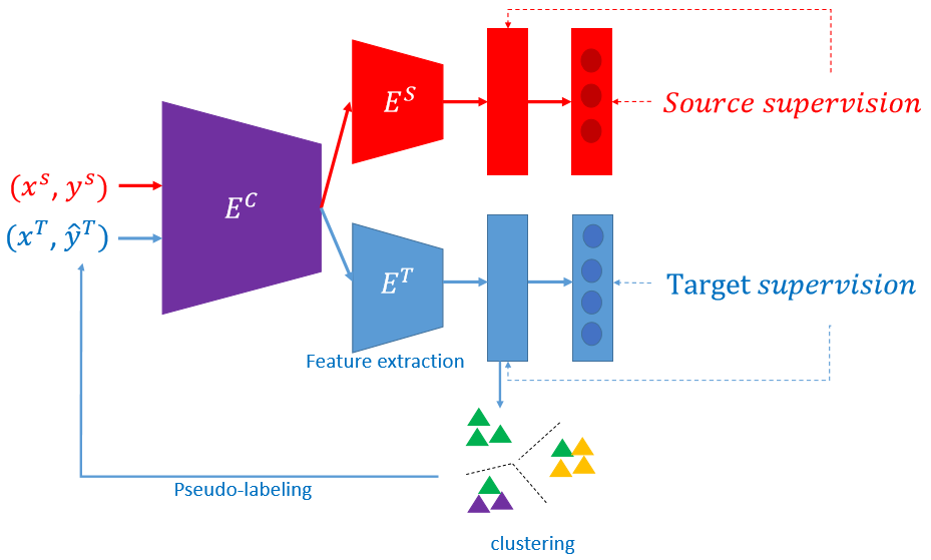
Domain adaptation for person re-identification
An unsupervised domain adaptation framework that allows adaptability to the target domain while ensuring robustness to noisy pseudo-labels
Smart annotation of visual data
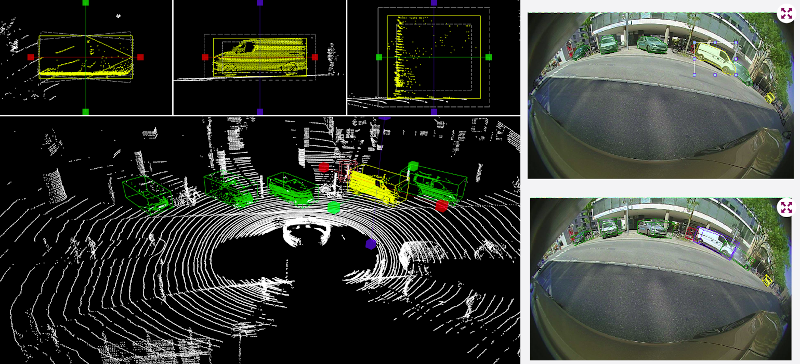
Multimodal visual data annotation
Fusion of 2D (RGB images from cameras) and 3D (point clouds from LIDAR) data for the annotation of 3D objects and scenes

Interactive detection and segmentation
Deep Learning algorithms for interactive instance segmentation requiring very little human effort
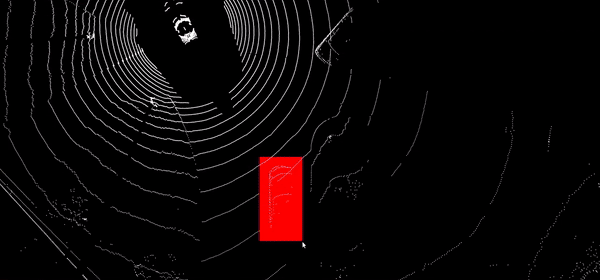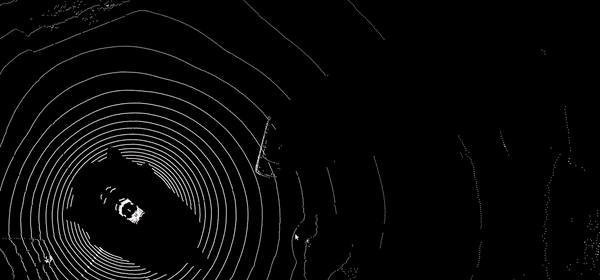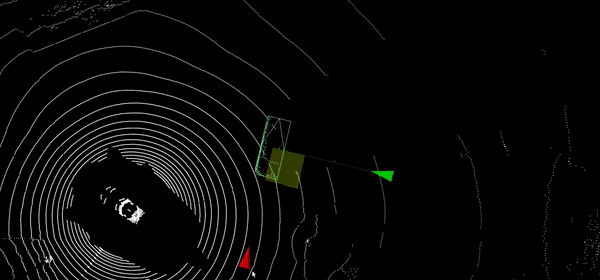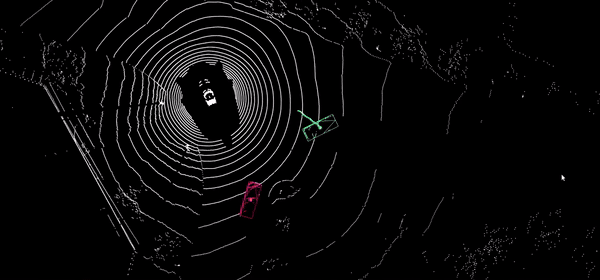
Automatic label temporal propagation
Automatic propagation of 2D and 3D annotations in time sequences by intelligent interpolation, visual tracking in images and point clouds

PIXANO: an opensource, smart annotation tool for Computer Vision applications
Efficient, large-scale, AI-automated image and video annotation solution offering a wide range of tools integrated into open, modular, reusable, and customizable web-based components.

Active learning for object detection and image segmentation
Relevant image mining and incremental learning of detection and segmentation models by optimizing the ratio between performance and number of labelled image
Reinforcement learning and perception models

Reinforcement learning for autonomous navigation
Learn representation of high-dimensional input data for training agents to navigate by reinforcement learning.
Trustworthy AI
Adversarial attacks and defense in deep metric learning
Self Metric Attack (SMA) and Furthest Negative Attack (FNA), two new adversarial attacks of metric embedding, and a new efficient extension of adversarial training protocol adapted to metric learning as a more robust defense