








L'apprentissage sans exemple (zero-shot learning - ZSL) [5] consiste à reconnaître des objets ou autres classes visuelles avec un modèle n'ayant utilisé aucun exemple desdites classes durant sa phase d'apprentissage. Pour palier ce manque d'information, chaque classe est associée à des prototypes sémantiques qui rend compte des caractéristiques de cette classe. Lors de la phase d'apprentissage, le modèle apprend à mettre en correspondance l'information visuelle et ces caractéristiques intermédiaires. Ainsi, durant la phase de test les images des classes non vues (unseen classes) peuvent être reconnues par le modèle.
Ce formalisme, mis en place à la fin des années 2000, a connu depuis quelques années un regain d'intérêt et les modèles proposés ont gagné en performances. Cela s'est aussi accompagné d'une définition plus précise de la tâche, afin de mieux correspondre à des cas d'usage réels. Les travaux du CEA List dans ce domaine s'inscrivent dans cette tendance et nous avons proposé plusieurs contributions pour s'approcher d'une utilisation du ZSL sur des cas réels.

La version généralisée de la tâche (generalized zero-shot learning - GZSL) permet, durant la phase de test, de reconnaître à la fois les classes non vues comme en ZSL classique, mais aussi les classes vues durant l’entraînement. En pratique, les modèles de ZSL classique sont alors fortement biaisés vers la reconnaissance de classes déjà vues.
Nous avons proposé une méthode permettant de sélectionner automatiquement les hyper-paramètres d'une méthode de ZSL classique afin d'améliorer ses performances dans le cas GZSL. En pratique, celles-ci sont améliorée de 48% sur CUB et 102% sur AWA2 [1].
Nous avons aussi identifié certaines hypothèses implicites des approches de ZSL qui pénalisent leur performances et proposé une séries de méthodes pour les corriger [2]. Là encore, cela aboutit à un gain de reconnaissance significatif [2].
Les prototypes sémantique consistent traditionnellement en une liste d'attributs (binaires) décrivant chaque classe, tels que « a un bec » ou « possède une fourrure ». Quand le nombre de classes devient grand (plusieurs centaines), et que le nombre de caractéristiques est grand, il devient fastidieux de créer de tels prototypes manuellement. Il est alors courant d'utiliser des prolongement léxicaux (word embeddings) pré-appris et calculés sur le nom des classes. Ce passage possible à l'échelle entraîne malheureusement une baisse drastique des perfromances.

Nous avons proposé de construire automatiquement des prototypes sémantiques à partir d'une information plus riche [3] ou en utilisant de grand corpus mieux adaptés à la descriptions de caractéristiques visuelles [4]. Ainsi, nous avons obtenus les meilleures performances reportées en 2020 sur ILSVRC en ZSL.
[1] Y. Le Cacheux, H. Le Borgne, M. Crucianu (2019) From Classical to Generalized Zero-Shot Learning: a Simple Adaptation Process, 25th International Conference on MultiMedia Modeling (MMM), Thessaloniki, Greece, January 8-11
[2] Y. Le Cacheux, H. Le Borgne and M. Crucianu (2019) Modeling Inter and Intra-Class Relations in the Triplet Loss for Zero-Shot Learning. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Seoul, Korea, Oct. 27 - Nov. 2
[3] Y. Le Cacheux, H. Le Borgne, M. Crucianu (2020) Webly Supervised Semantic Embeddings for Large Scale Zero-Shot Learning Task-CV workshop@ECCV, Online, 23-28 August 2020
[4] Y. Le Cacheux, A. Popescu, H. Le Borgne (2020) Using Sentences as Semantic Representations in Large Scale Zero-Shot Learning, Asian Conference on Coputer Vision (ACCV), Kyoto, 2020
[5] Y Le Cacheux, H Le Borgne, M Crucianu (2021) Zero-shot Learning with Deep Neural Networks for Object Recognition, In : J. Benois Pineau and A. Zemmari (Eds.) Multi-faceted Deep Learning. Springer, 2021. Chap. 6, p. 273-288.
Les modèles d’apprentissage profond standard sont développés fonctionnent très bien avec des données statiques et disponibles à tout moment. Toutefois, l’hypothèse de la disponibilité permanente des données n’est pas vérifiée dans bon nombre de cas applicatifs. Les données peuvent devenir indisponibles pour des raisons de protection de la vie privée, comme c’est le cas lors des apprentissages multi-site sur des données médicales, ou à cause d’une mémoire limitée, comme c’est la cas pour les applications embarquées. Dans le cas des données dynamiques, l’agent artificiel doit apprendre de manière incrémentale (ou continue) afin d’intégrer de nouvelles connaissances sans avoir accès aux données passées ou avec un accès limité. Il est notamment confronté au phénomène d’oubli catastrophique qui consiste en une très forte dégradation des performances pour les classes passées lors de l’intégration de nouvelles connaissances. Depuis 2018, le CEA LIST a proposé des algorithmes d’apprentissage incrémental qui sont adaptés aux deux situations, avec l’accent mis sur la scalabilité des algorithmes.
Quand une mémoire limitée du passé est disponible, les recherches [2,3,4] ont montré que l’usage de la distillation des connaissances, répandu dans la communauté, est inutile ou même contre productif à grande échelle. L’apprentissage incrémental se prête bien inspirée par des algorithmes classiques d’apprentissage déséquilibré [4,6] qui sont plus simples que les méthodes concurrentes et au moins aussi performantes.

L’apprentissage incrémental est encore plus difficile lorsqu’aucune mémoire du passé n’est disponible. Une approche par transfert [1] s’avère très efficace si la quantité de données initiales est suffisante et si les classes nouvelles ne sont pas radicalement différentes des classes initiales [6]. Dans ce dernier cas, il est nécessaire de mettre à jour le modèle profond pour les nouvelles classes et cela est fait classiquement en utilisant un “fine tuning” avec distillation de connaissances. Le CEA LIST a très récemment proposé une approche différente [5] qui exploite les classifieurs appris initialement pour chaque classe passée et applique une normalisation afin de rendre le prédictions des anciennes et nouvelles classes équitables. Cette méthode obtient des résultats significativement meilleurs que les méthodes existantes, tout en étant plus simple.
[1] E. Belouadah A. Popescu "DeeSIL: Deep-Shallow Incremental Learning", Proceeding of ECCV Workshops 2018.
[2] E. Belouadah A. Popescu "Il2m: Class incremental learning with dual memory", Proceeding of ICCV 2019.
[3] E. Belouadah A. Popescu "ScaIL: Classifier Weights Scaling for Class Incremental Learning", Proceeding of WACV 2020.
[4] E. Belouadah A. Popescu, I. Kanellos "Initial Classifier Weights Replay for Memoryless Class Incremental Learning", Proceeding of WACV 2020.
[5] E. Belouadah, A. Popescu, U. Aggarwal, L. Saci "Active Class Incremental Learning for Imbalanced Datasets", Proceeding of ECCV Workshops 2020.
[6] E. Belouadah A. Popescu, I. Kanellos "Initial Classifier Weights Replay for Memoryless Class Incremental Learning", Proceeding of BMVC 2020.
[7] E. Belouadah A. Popescu, I. Kanellos “A Comprehensive Study of Class Incremental Learning Algorithms for Visual Tasks”, Neural Networks 135, 38-54
[8] H Slim, E Belouadah, A Popescu, D Onchis, Dataset Knowledge Transfer for Class-Incremental Learning Without Memory, WACV 2022
Les modèles d'apprentissage neuronaux sont performants mais nécessitent une grande quantité de données annotée précisément pour régler leurs paramètres. De telles conditions ne sont néanmoins pas réunies pour la plupart des cas d'usage réels. En pratique, il est courant de disposer de peu de données annotées, et leur production est souvent un processus coûteux en temps, en matériel, et peut nécessiter une expertise rare pour certains domaines spécialisés. De plus, une fois le modèle appris, il est généralement figé et le faire évoluer nécessite souvent de le réapprendre entièrement, processus à nouveau long et coûteux.
Depuis 2014, le CEA List a mis en place la technologie Semfeat, qui permet de reconnaître des dizaines de milliers de classes, d'en ajouter et d'en retirer à volonté et de surtout d'effectuer cette annotation rapidement et efficacement. De plus, cela fournit aussi une description d'image particulièrement efficace pour la recherche de contenu visuel à grande échelle. Ces recherches académiques sont progressivement intégrées à une brique industrialisée pouvant être déployée dans des systèmes d'information variés.
Le principe du transfert consiste à décrire les images au moyen d'un « modèle cœur » fixe, puis d'apprendre un modèle léger pour chaque concept visuel d'intérêt [1]. Chaque concept est appris à partir d'un nombre limité d'exemples annotés, qui peuvent être collectés automatiquement sur le Web puis « nettoyés » afin d'éviter tout travail manuel [2].


Un nombre réduit de concepts visuels peut être sélectionné, de manière à fabriquer une représentation « creuse » de l'image, particulièrement performante dans un contexte de recherche par le contenu visuel [1, 3, 4]. Nous avons également développé une technologie d'indexation liée à cette propriété permettant de retrouver une image à complexité quasi-indépendante de la taille de la base [5, 5a].
Les images étant décrites selon des concepts sémantiques, il est possible de fusionner ces signatures avec des représentation de contenu textuel, améliorant encore les capacité de classification ou de recherche par le contenu, et permettant de décrire des documents multimédia comportant contenu visuel et textuel [6].


Le « réseau cœur » est lui-même appris sur une base d'apprentissage « source », et les descriptions induites sont moins performantes quand le problème d'intérêt « cible » est très différent du problème source. Nous avons développé des méthodes permettant de rendre le réseau cœur plus universel, c'est-à-dire à le rendre performant sur un plus grand nombre de problèmes cibles. L'intérêt de notre approche est qu'elle est très économe en travail manuel supplémentaire, le réduisant typiquement d'un facteur 1000 par rapport aux approches précédentes [7, 8].
[1] A. Gînsca, A. Popescu, H. Le Borgne, N. Ballas, D. P. Vo, I. Kanellos, Large-scale Image Mining with Flickr Groups, 21st International Conference on Multimedia Modelling (MMM2015), 5-7 january 2015, Sydney, Australia, 2015.
This paper receives the best paper award at MMM 2015
[2] P. Vo, A. Ginsca, H. Le Borgne and A. Popescu, Harnessing Noisy Web Images for Deep Representation, Computer Vision and Image Understanding, Volume 164, November 2017, Pages 68-81
[3] Y. Tamaazousti, H. Le Borgne and C. Hudelot, Diverse Concept-Level Features for Multi-Object Classification, Proc. ACM International Conference on Multimedia Retrieval (ICMR 2016), New York, USA, June 2016
[4] Y. Tamaazousti, H. Le Borgne and A. Popescu, Constrained Local Enhancement of Semantic Features by Content-Based Sparsity, Proc. ACM International Conference on Multimedia Retrieval (ICMR 2016), New York, USA, June 2016
[5] A. Popescu, A. Gînsca, H. Le Borgne, Scale-Free Content Based Image Retrieval (or Nearly So), The IEEE International Conference on Computer Vision Workshop (ICCVW) on Web-Scale Vision and Social Media, 2017, pp. 280-288
[5a] Method and system for searching for similar images that is nearly independent of the scale of the collection of images. US Patent App. 15/763,347
[6] Y. Tamaazousti, H. Le Borgne, A. Popescu, E. Gadeski, A. Gînsca, and C. Hudelot, Vision-language integration using constrained local semantic features, Computer Vision and Image Understanding, vol. 163, pp 41-57, october 2017
[7] Y. Tamaazousti, H. Le Borgne and C. Hudelot, MuCaLe-Net: Multi Categorical-Level Networks to Generate More Discriminating Features, Computer Vision and Pattern Recognition (CVPR 2017), Hawaii, USA, July 2017
[8] Y. Tamaazousti, H. Le Borgne, C. Hudelot, M.E.A Seddik, M. Tamaazousti (2019) Learning More Universal Representations for Transfer-Learning, IEEE T. Pattern Analysis and Machine Intelligence (PAMI) (pre-print 2019)
De par son positionnement à l’interface entre la recherche académique et les besoins industriels, le LIST est confronté à la nécessité d’adapter les outils qu’il développe à des contextes applicatifs divers, ce qui représente à la fois une difficulté du point de vue de la réalisation d’applications industrielles mais aussi une problématique de recherche de plus en plus prégnante.
Le LIST développe ainsi différentes stratégies pour minimiser l’effort d’adaptation à un nouveau contexte applicatif. L’une d’elles consiste à s’appuyer sur des processus non supervisés. Les travaux menés dans le cadre de l’extraction d’information ouverte (open information extraction) [1] ont ainsi montré la possibilité d’extraire des relations de façon générique à partir d’un corpus et de caractériser leur type a posteriori par le biais de processus de regroupement. Cette capacité a été appliquée en particulier au domaine de la sécurité dans le cadre du projet ePOOLICE et au domaine médical. Le même type de problématique a été étendu aux schémas d’événements grâce à des approches bayésiennes hiérarchiques [2] et se décline pour ces mêmes schémas d’événements au travers du projet ASRAEL pour les contenus journalistiques.
[1] Wei Wang, Romaric Besançon, Olivier Ferret, and Brigitte Grau. Semantic clustering of relations between named entities. In 9th International Conference on Natural Language Processing (PolTAL 2014), pages 358–370, Warsaw, Poland, september 2014. Springer International Publishing.
[2] Kiem-Hieu Nguyen, Xavier Tannier, Olivier Ferret, and Romaric Besançon. Generative event schema induction with entity disambiguation. In 53r d Annual Meeting of the Association for Computational Linguistics and 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2015), pages 188–197, Beijing, China, July 2015.
Au-delà de l’analyse linguistique au niveau phrastique, une part importante des recherches se focalisent sur les problématiques complémentaires d’extraction et de synthèse d’information, avec des applications en lien avec la veille.
L'extraction d'information intervient au niveau macroscopique des événements en considérant les tâches de détection supervisée de ces événements et de leurs arguments. Les travaux menés sur cette thématique [1] mettent particulièrement l’accent sur la prise en compte du niveau discursif en dépassant le cadre souvent privilégié de la phrase. Ils s’enrichissent en outre de la mise en évidence des relations entre événements, que ce soient des relations temporelles [2] ou de coréférence, explorées toutes deux dans le domaine médical.
[1] Dorian Kodelja, Romaric Besançon, and Olivier Ferret. Exploiting a more global contextfor event detection through bootstrapping. In 41st European Conference on Information Retrieval (ECIR 2019) : Advances in Information Retrieval, short article session, pages 763–770, Cologne, Germany, 2019. Springer International Publishing
[2] Julien Tourille, Olivier Ferret, Xavier Tannier, and Aurélie Névéol. Neural architecture for temporal relation extraction : A bi-lstm approach for detecting narrative containers. In 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017), short paper session, pages 224–230, Vancouver, Canada, July 2017.
[3] Dorian Kodelja, Romaric Besançon, and Olivier Ferret, Dynamic Cross-Sentential Context Representation for Event Detection, European Conference on Information Retrieval, (ECIR 2021), pages 295-302
Les travaux sur la synthèse d’information s’inscrivent dans le cadre du résumé multi-document par extraction en y intégrant dans leur déclinaison la plus récente une dimension de mise à jour temporelle exploitant, dans un même cadre d’optimisation linéaire en nombres entiers, la similarité sémantique des phrases fondée sur des plongements lexicaux [1] et la structure discursive des textes selon le paradigme de la rhetorical structure theory (RST).
[1] Maâli Mnasri, Gaël de Chalendar, and Olivier Ferret. Taking into account inter-sentence similarity for update summarization. In Eighth International Joint Conference on Natural Language Processing (IJCNLP 2017), short paper session, pages 204–209, Taipei, Taiwan, November 2017. Asian Federation of Natural Language Processing.
La désambiguïsation d’entités consiste à lier automatiquement des mentions d’entités identifiées dans un texte et des entités présentes dans une base de connaissances. L’approche générale consiste à produire, pour une mention donnée, des entités candidates puis à sélectionner la meilleure parmi celles-ci, selon un ensemble de critères.
Nous avons développé une méthode de fondée sur l’apprentissage de modèles permettant d’opérer une discrimination entre une entité et les entités qui lui sont ambiguës. Un verrou majeur dans ce contexte réside dans la capacité à gérer de grandes bases de connaissances nécessitant l’apprentissage de dizaines de millions de modèles. Nous proposons trois stratégies permettant d’y répondre, offrant différents compromis entre efficacité et qualité de reconnaissance [1].
Quand le contexte textuel est relativement limité, comme cela est la cas dans des tweets, nous profitons de l'information visuelle pour aider à la désambiguïsation.
Notre modèle extrait puis intègre diverses informations textuelles et visuelles , dans le document et la base de connaissance, dans un unique modèle neuronal [2].

Cette tâche étant nouvelle, nous avons développé une méthode permettant de construire, automatiquement et à la demande, un corpus d'évaluation à partir de Twitter [3]. La base de connaissance contient plus de 2,5 millions d'entrées, chacune étant ambiguë par construction. Sur un corpus d'évaluation contenant presque 10^5 documents (dont un tiers pour le test), notre modèle [2] désambiguïse correctement 80% des entités.

[1] H. Daher, R. Besançon, O. Ferret, H. Le Borgne, A-L. Daquo, and Y. Tamaazousti, Supervised Learning of Entity Disambiguation Models by Negative Sample Selection, International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2017), Budapest, Hungary, April 2017
[2] O. Adjali, R. Besançon, O. Ferret, H. Le Borgne and B. Grau (2020) Multimodal Entity Linking for Tweets, 42nd European Conference on Information Retrieval (ECIR): Advances in Information Retrieval
[3] O. Adjali, R. Besançon, O. Ferret, H. Le Borgne and B. Grau, (2020) Building a Multimodal Entity Linking Dataset From Tweets, 12th International Conference on Language Resources and Evaluation (LREC)
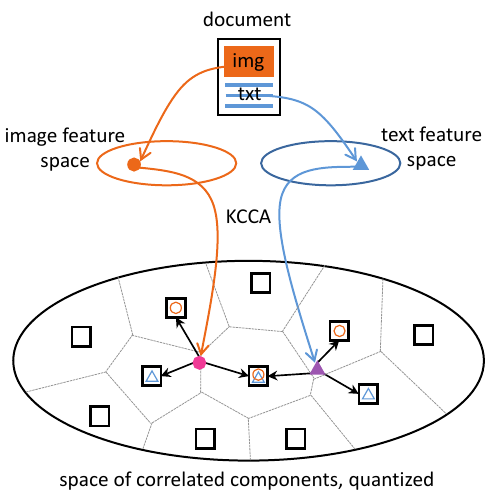
Retrouver une image correspondant à un texte permet par exemple d'illustrer ce dernier de manière pertinente, ou encore de rechercher des contenus correspondants. Nous avons exploré des approches où texte et images sont représentés dans un même espace vectoriel. Ainsi, le rapprochement de contenues textuels et visuels, ou de contenus multimodaux, est significativement facilité.
Le contenu textuel véhicule naturellement unne sémantique haut niveau, alors que les images ont des représentations plus proches des pixels bas-niveau. Ainsi, au sein d'espaces joints, les documents ont tendance à se regrouper plus fortement « par modalité » que selon leur sémantique.

Nous avons proposé une nouvelle représentation intrinsèquement multimodale, selon laquelle un document est projeté sur plusieurs « pivots » représentatifs de portions de l'espace joints quantifié [1]. Cette approche permet d'acrroître le découplage entre modalités au sein de l'espace joint, afin que le rapprochement des documents reflète plus fortement leur sémantique.
Nous avons aussi proposé d'utiliser une ensemble de données multimodales auxiliaire qui, en servant de pivot supplémentaire, permet de compléter des représentation unimodales et les rendre intrinsèquement multimodales [2]. Dans de tels espaces, le rapprochement de documents est également amélioré.

De manière encore plus intéressante, la conjonction de ces approches permet d'envisager une classification cross-modale. Ainsi, un classifieur appris à partir de textes peut être directement appliqué à un contenu visuel.
[1] T. Q. N. Tran, H. Le Borgne, M. Crucianu, Aggregating Image and Text Quantized Correlated Components, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2046-2054 , 27th june – 1st july 2016
[2] T. Q. N. Tran, H. Le Borgne, M. Crucianu, Cross-modal Classification by Completing Unimodal Representations, ACM Multimedia 2016 Workshop:Vision and Language Integration Meets Multimedia Fusion, Amsterdam, The Netherlands, October 16, 2016
LIMA est un analyseur linguistique disponible en licence libre et propriétaire AGPL.
En dépit du développement récent des approches de bout en bout, le traitement du texte reste dépendant d’une analyse linguistique capable d’intégrer les spécificités propres aux différentes langues existantes. Pour gérer la problématique du multilinguisme qui en résulte, le CEA LIST développe depuis plusieurs années la plateforme d’analyse linguistique LIMA (LIbre Multilingual Analyzer), qui offre la modularité nécessaire à la prise en compte la plus générique possible d’un large ensemble de langues tant du point de vue
des traitements que de leurs ressources. Cette plateforme, sous licence libre AGPL prend en charge à des degrés divers l’analyse linguistique principalement au niveau phrastique en allant de la segmentation en mots jusqu’à l’analyse en rôles sémantiques.
Les dernières avancées en matière de réseaux de neurones ainsi que la mise à disposition d'ensembles de textes annotés dans différentes langues par l'association Universal Dependencies ont permis d'améliorer considérablement son efficacité ainsi que le nombre de langues traitées, mais également d'enrichir le logiciel de trois modules d'apprentissage. Le premier module permet de segmenter les textes en mots et phrases, un deuxième effectue l'analyse morphologique, lexicale et syntaxique, et le troisième l'annotation des entités nommées.
Tandis que la version historique de LIMA est capable d'analyser 6 langues (anglais, français, allemand, espagnol, portugais, chinois et arabe), la nouvelle version Deep LIMA peut désormais analyser plus de 60 langues avec des performances à l'état de l'art. Le logiciel est essentiellement écrit en C++ mais peut être facilement installé via pypi pour une intégration en python.

Les performances actuelles de LIMA dans toutes les langues prises en charge sont indiquées sur la page dédié du projet. Nous en rapportons quelques-uns ci-dessous, pour l'anglais et le français uniquement.
Concernant la vitesse, il est important de noter que LIMA et UDify effectuent des calculs multithread et consomment normalement tous les cœurs de CPU disponibles. UDPipe n'utilise qu'un seul thread. Cette différence est ignorée ici.
eng English-EWT
Tool
Mode
Tokens
Sentences
Words
UPOS
UFeats
Lemmas
UAS
LAS
Speed
lima
raw
98.85
85.14
98.85
94.89
90.81
94.17
85.15
82.06
245
lima
gold-tok
100
100
100
95.95
91.86
95.09
87.91
84.65
254
udpipe
raw
98.9
86.92
98.9
93.34
94.3
95.45
81.83
78.64
1793
udpipe
gold-tok
100
100
100
94.43
95.37
96.41
84.4
81.08
2281
udify
gold-tok
100
100
100
96.29
96.19
97.39
91.12
88.53
92
fra French-Sequoia
Tool
Mode
Tokens
Sentences
Words
UPOS
UFeats
Lemmas
UAS
LAS
Speed
lima
raw
99.69
84.22
97.94
96.06
89.28
94.91
85.09
82.4
291
lima
gold-tok
100
100
100
98.25
91.33
96.91
89.1
86.48
300
udpipe
raw
99.79
87.5
99.09
96.1
94.93
96.93
84.85
82.09
3349
udpipe
gold-tok
100
100
100
97.08
95.84
97.82
86.83
84.13
3349
udify
gold-tok
100
100
100
97.93
89.41
97.24
92.07
89.22
86
- V. Bocharov, G. de Chalendar (2020) The Russian language pipeline in the lima multilingual analyzer Komp'juternaja Lingvistika i Intellektual'nye Tehnologii
- G. de Chalendar (2018) Nouveautés de l’analyseur linguistique LIMA, In: Actes de la conférence Traitement Automatique de la Langue Naturelle, TALN 2018 : Volume 2 : Démonstrations, articles des Rencontres Jeunes Chercheurs, ateliers DeFT. May 2018, Rennes, France. 2018. hal-01843585
- G. de Chalendar (2014). The LIMA Multilingual Analyzer Made Free : FLOSS Resources Adaptation and Correction. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC-2014), Reykjavik, Iceland, May 26-31, 2014., p. 2932–2937.
- R. Besançon, G. De Chalendar, O. Ferret, F. Elkateb-Gara, O. Mesnard, M. Laïb, N. Semmar (2010) Lima: A multilingual framework for linguistic analysis and linguistic resources development and evaluation, Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC'10)

CLIMA, le configurateur de LIMA, permet d'initialiser et de modifier les fichiers de configuration et les ressources linguistiques de LIMA pour analyser les documents d'un nouveau domaine spécifique, en précisant les informations à extraire sous la forme d'une liste d’entités connues (décrites dans des fichiers textes ou une base de connaissances, de type mind map) et de documents annotés.

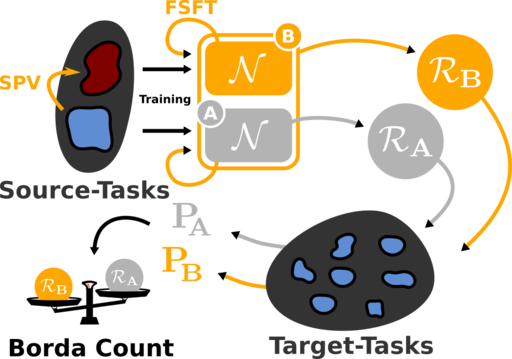
Une grande majorité d'Européens utilisent les réseaux sociaux en ligne (OSN) et beaucoup d'entre eux pensent qu'ils n'ont pas assez de contrôle sur les données qu'ils partagent et sont préoccupés par la façon dont ces données sont traitées par les OSN. En réponse à ces préoccupations, le List développe des outils qui donnent aux utilisateurs les moyens d'exercer un contrôle accru sur les données qu'ils distribuent ou avec lesquelles ils interagissent.
Nos premiers travaux ont été menés dans le cadre du projet européen FP7 USEMP qui abordait directement ces problèmes. Il a réuni non seulement des experts de la gestion multimédia, mais aussi des juristes et des spécialistes des sciences sociales [1].
Dans le cadre de USEMP, nous avons proposé un système qui annote les images dans le respect de la vie privée. Nous montrons que les modèles génériques de protection de la vie privée donnent de mauvais résultats avec des ensembles de données réelles dans lesquels les images sont fournies par les individus parce qu'ils ignorent la nature subjective de la vie privée. C'est pourquoi nous développons des modèles personnalisés de classification de la vie privée qui, en utilisant de petites quantités de commentaires des utilisateurs, offrent des performances nettement meilleures que les modèles génériques [2].
[1] A. Popescu et al. (2015) Increasing transparency and privacy for online social network users–USEMP value model, scoring framework and legal, Annual Privacy Forum, 38-59
[2] E. Spyromitros-Xioufis, S. Papadopoulos, A. Popescu, Y. Kompatsiaris (2016) Personalized Privacy-aware Image Classification, Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, pp 71-78, ACM, 2016
[3] VK Nguyen, A Popescu, J Deshayes-Chossart, Unveiling real-life effects of online photo sharing, WACV 2022
