
We conduct research to better understand multimedia (text, image, speech, videos) and multilingual content. We filter, structure and organise the information in order to provide an easier access to the user.
We develop efficient and robust algorithm to analyze, classify and retrieve multimedia content and extract relevant information from it. A particularity of the team is to rely simultaneously on several modalities (e.g visual and textual) to benefit from complementarities. Hence, our works deal with both natural language processing and computer vision.
Many of the methods we developp aim at being more efficient on large scale use case. We also aim at addressing the difficulties that on meet on real data, that contain “noise” under may forms, are not well calibrated, not balanced and more generally not as expected by the usual academic approaches.
Research topics
Multilingual Linguistic Analysis
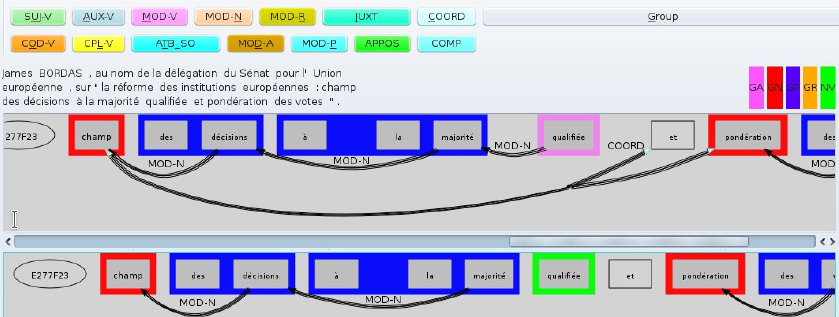
Linguistic Analyser
LIMA is a multilingual linguistic analyzer supporting more than 60 language and available under a dual licensing model.
Semantic information extraction

Filtering and structure information
We identify the relevant terms of a specialized domain
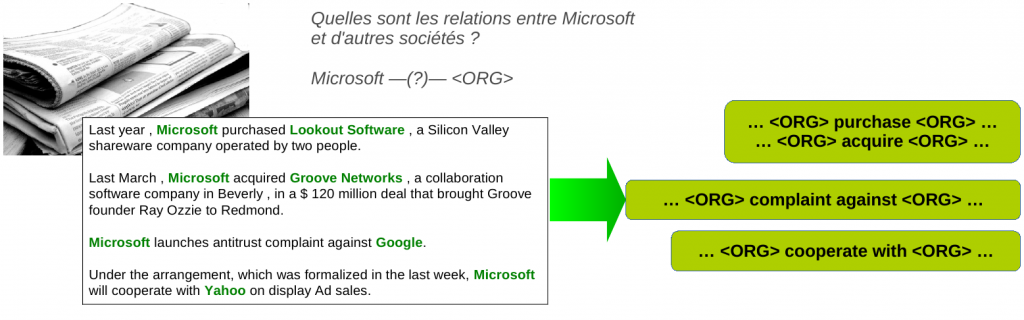
Unsupervised Relation Extraction
The work carried out in the context of open information extraction has shown the possibility of extracting relations generically from a corpus and of characterising their type a posteriori through aggregation processes.

Information Synthesis
It is possible to summarise several documents simultaneously by extraction, integrating a temporal updating dimension.
Cheap learning
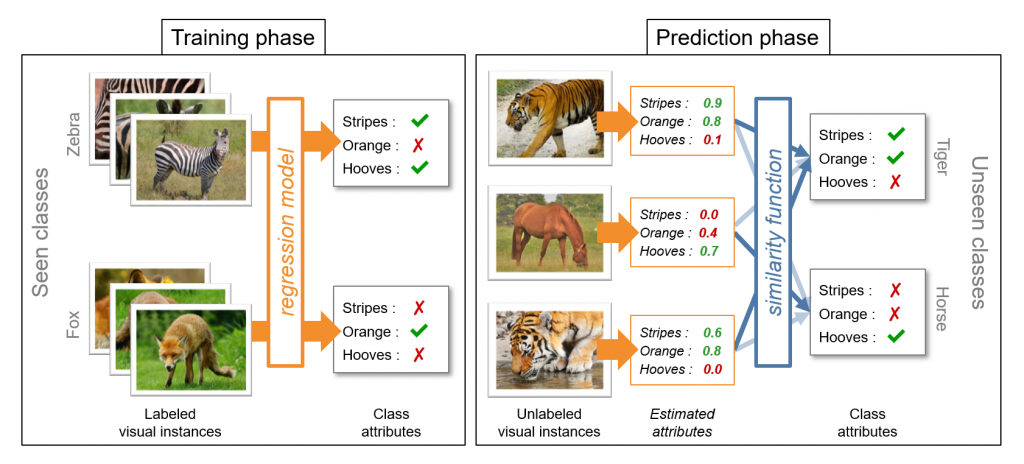
Recognizing objects without visual sample
Zero-shot learning aims at recognising objects in image without any visual sample during learning. It relies on a semantic description of the class, made from textual content.
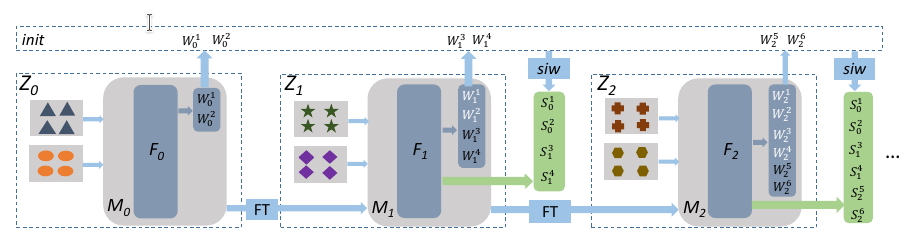
Incremental learning
AI systems can be updated with streamed data, while being computationaly efficient and a bounded memory.
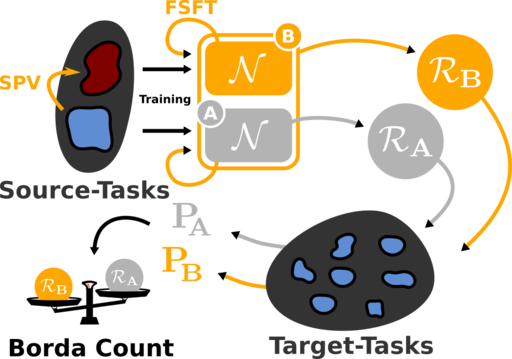
Fast and Efficient Transfer Learning
The Semfeat technology allows classify an image among dozens of thoushands possible visual concepts, while being fast and robust. The concepts can be easily added or removed, with a limited cost in terms of manual annotations need. It also allows to retrieve similar content to a query image into a large dataset, with a coplexity that is almost indemendent from the dataset size.
At the core of technology, “universal networks” provide a fast adaptation to a new use case, while keeping performances and still at a low cost of manual work.
Cross-modal Analysis
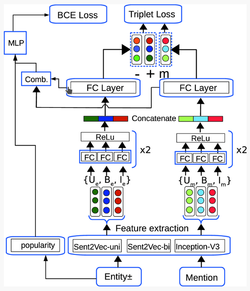
Multimedia Entity Linking
Entity Linking consists to connect an entity mention in a text to a known entity in a knowledge base that has several millions entries. In a context of short texts (tweets) we rely on the visual information to improve performances.
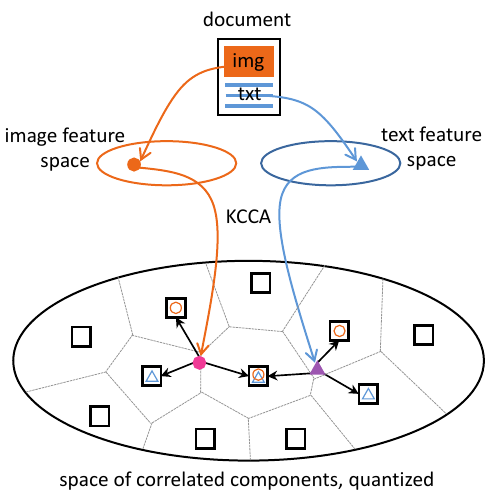
Cross-Modal Retrieval and Classification
We learn joint space of the visual and textual content to “translate” information from one modality to another. Hence it allows to easily find an image from a texte or the contrary. We can even build a textual classifier from images and reciprocally.
User Centered Applications
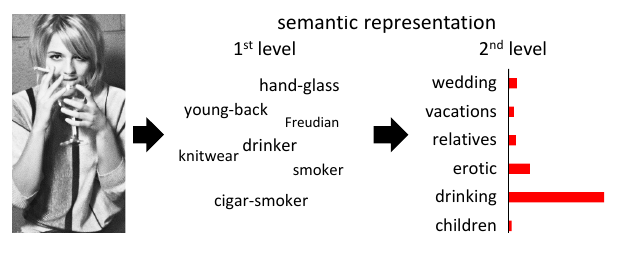
Privacy
We help user to gain empowerment for their AI tools usage