



















Fine-grained object recognition is the problem of discriminating classes of objects that are very close in appearance. A typical use case is vehicle make and model recognition. In addition to the strong inter-class similarity, it is difficult to build large annotated datasets to train a robust deep model. Fine-grained recognition algorithms based on 3D CAD models have been developed at CEA LIST [1]. The use of these synthetic data allows to considerably reduce the cost of annotation: a single CAD model can automatically generate a large number of images of a vehicle from several viewpoints. Domain adaptation strategies by using common features between natural and synthetic images allow the generalization of the model to apply it to real use cases.
[1] Deep edge-color invariant features for 2D/3D car fine-grained classification, F. Chabot, M. Chaouch, J. Rabarisoa, C. Teulière, T. Chateau, IEEE Intelligent Vehicle Conference (IV) 2017

A multi-task neural network estimates several types of predictions in parallel. This type of architecture allows the optimization of computation time during inference by using a single unified model. These networks also learn common visual characteristics between different tasks, allowing a better generalization of the model. We have developed Deep MANTA [1], a multi-task network for 2D and 3D object detection from a monocular image. Research work has allowed to make the network lighter in order to deploy it in autonomous vehicles. Other scene analysis tasks such as semantic segmentation and depth map prediction were also added to the model to obtain a complete description of the scene.
[1] Deep MANTA: a coarse-to-fine many-task network for joint 2D and 3D vehicle analysis from monocular image, F. Chabot, M. Chaouch, J. Rabarisoa, C. Teulière, T. Chateau, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2017



The objective of this work is to propose a method to estimate the 3D pose of all people in an RGB image.
Such a challenge involves several research topics such as human detection for localizing people in the complete scene, 2D skeleton estimation since it is closely related to 3D skeleton, and transfer learning for generalizing features learnt on « lab » dataset to « in the wild » one. Finally, such a technology is particularly interesting when suitable to real time applications. Therefore, the low complexity of the algorithm is also a main challenge.
In PandaNet[1], we want to solve at the same time the detection, the 2D and 3D pose estimation problems. To do so, we rely on the Lapnet architecture also developed in the lab, a single shot model with strategies for dealing with small and occluded objets. On top of this detector, we build the PandaNet architecture, which focuses on both on 2D/3D pose estimation as additional tasks.
[1] PandaNet : Anchor-based single-shot multi-person 3d pose estimation , Benzine, A., F. Chabot, B. Luvison, Q. C. Pham et C. Achard, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020



Modeling a person's appearance is useful for associating different views of a person, i.e. for re-identifying this person. Person re-identification is a very active research topic and a key functionality for videosurveillance. It is the core element of applications such as automated person search and multi-camera person tracking. It consists in retrieving occurrences of a person from a set of images. Despite the many studies on this topic in the past few years, modeling human appearance remains a challenge. Indeed, re-identification models have to discriminate distinct people while being robust against the high variability of their visual appearance. Besides, in real use-case scenarios, image snippets around the people are not available. Thus, re-identification results also depend on the quality of a detector that localizes people in the scene. Person search is the problem considering both detection and re-identification tasks in a unique framework.
At CEA-LIST, a new end-to-end CNN architecture [1] based on a single-shot detector (SSD) architecture has been proposed. It is 1.5 to 8 times faster than disjoint models and is competitive with state-of-the-art methods on PRW [2] (cf. illustration above) and CUHK-SYSU datasets. Moreover, first results show that feature maps learned from aggregated detection datasets also lead to better re-identification performance when applied to cross-dataset scenarios, i.e, when no training set is available for the target dataset.
Below, a video illustration of one of our re-identification models with queries and galleries from the Visdrone [3] dataset. Unlike in tracking algorithms, results are independent from frame to frame.
[1] End-To-End Person Search Sequentially Trained On Aggregated Dataset, Loesch A., Rabarisoa J., Audigier R., IEEE International Conference on Image Processing (ICIP) 2019
[2] Person re-identification in the wild, Zheng, L., Zhang, H., Sun, S., Chandraker, M., Yang, Y., & Tian, Q., IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017
[3] Vision meets drones: A challenge, Zhu, P., Wen, L., Bian, X., Ling, H., & Hu, Q., arXiv preprint arXiv:1804.07437 2018

Instance-level human parsing in the wild is an important task that can support different application domains such as video surveillance or human behavior analysis. Many methods focus on the semantic segmentation of clothing attributes and body parts of a single person (for fashion applications mostly). However, instance-level human parsing in the wild implies the association of each detected semantic attribute to a human instance as an additional constraint (cf. above illustration on images from CIHP dataset [1]).
At CEA-LIST, we address the issue by proposing a multi-task deep neural network model that solves the task of semantic attribute segmentation and the task of person instance segmentation simultaneously with a single-shot architecture. It leads to constant inference time independent of the number of people detected in the images. Moreover, our method is end-to-end and does not need any additional refinement branch or post-processing to obtain the person masks. Our approach performs competitive results compared with the state of the art, while being faster.
Below, illustration of our instance-level human parsing predictions on images of the CIHP validation set.
[1] Instance-level human parsing via part grouping network, Gong, K., Liang, X., Li, Y., Chen, Y., Yang, M., & Lin, L., European Conference on Computer Vision (ECCV) 2018

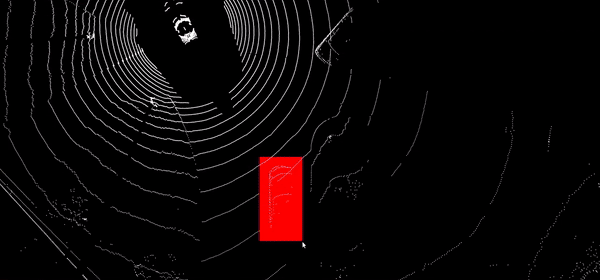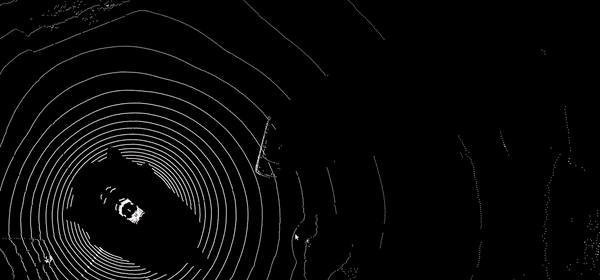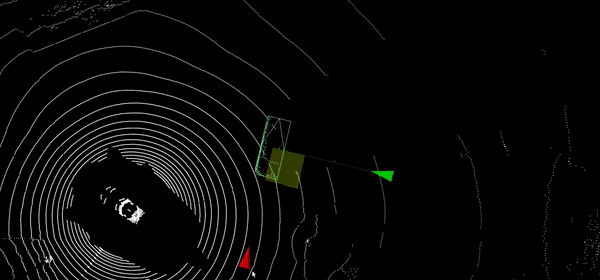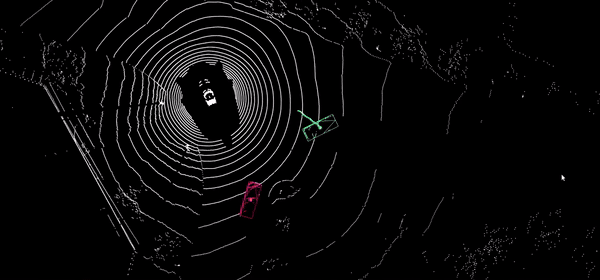
The goal is to track in real time and simultaneously all objects of different kind from one or multiple cameras in the image or in a 3D reference of the environement.
Visual tracking is a complex process involving several technologies such as object detection, visual description of objects, spatial and temporal association of observations and camera calibration. Since real-time tracking is a markovian process, an error can durably impact one or several tracked objects. It is necessary to properly use the different algorithmic modules to guarantee track consistency as long as possible.
Similarly to state of the art approaches that rely on robust detection and re-identification process(Deep SORT, FairMOT), our tracking technologies rely on our own detectors and reID models on which we build up 3D geometric reasoning obtained from skeleton estimation and camera calibration.

Objective
The aim is to recognise all possible interactions between objects and people and also between people. This technology allows a fine analysis of a scene and can be applied in video surveillance to detect fights or abandoned luggage for example.
The challenges
It is necessary to detect all the objects in a scene beforehand, which is a research axis in its own right. Once these objects are detected, it must be possible to associate them with the right type of interaction. An interaction such as "holding" can be carried out with a multitude of different types of objects. The algorithm must be able to detect the interaction even if it has never seen a person holding a certain type of object during learning: it must be able to generalise the interaction. Moreover, objects in interaction are sometimes hidden or not visible in the scene. In these cases, the algorithm must still be able to recognize the interaction just with the appearance of the person. Finally, some semantically different interactions are visually close such as eating and drinking or holding and lifting.
The proposed solution
The main majority of state of the art methods detect all the objects in the scene beforehand and then calculate a probability of interaction between all possible pairs. The calculation time required to process an image is therefore quadratic and depends on the number of objects in the scene.
CEA LIST proposes the CALIPSO (Classifying all interacting pairs in a single shot) solution [1], which is a state-of-the-art single shot method because it estimates the interactions by passing the image through the network only once. To do this, the interactions are estimated on a dense grid of anchors. One strength of CALIPSO is that it is fast and independent of the number of objects in the image.
The dataset used
We use the V-COCO dataset which consists of 10,000 images and is annotated with about 30 interaction verbs.
[1] Classifying All Interacting Pairs in a Single Shot, S. Chafik, A. Orcesi, R. Audigier, B. Luvison, in IEEE Winter Conference on Applications of Computer Vision (WACV) 2020

Objective
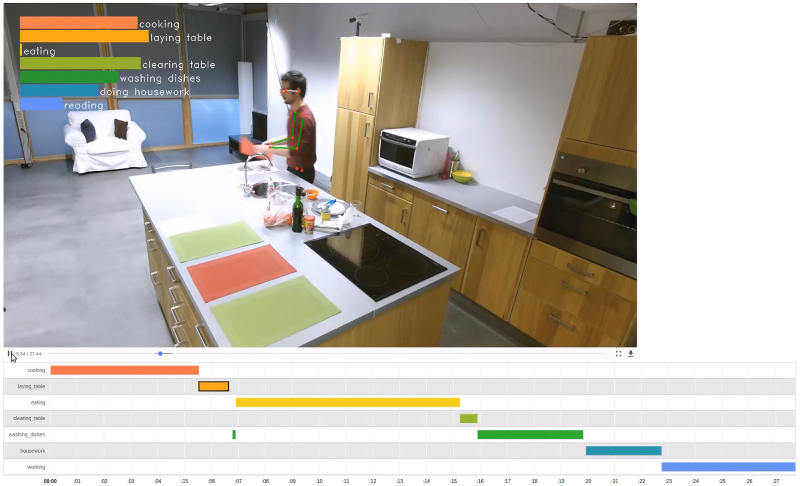
The objective is to recognise an activity and to locate it in time. The CEA is applying this technology in the context of Smart Home, where the use cases are diverse. Indeed, the recognition of activities is useful for the assistance of elderly people at home. Thanks to this technology, it is possible to locate a person’s daily activities. The fact that he or she is no longer doing this or that activity as usual may indicate a loss of autonomy. Activity recognition is also used in a home automation context to improve the comfort of the inhabitants. This results in an adaptation of the light and sound environment to the person’s activity.
The database used
The CEA has created the DAHLIA (Daily Home Life Activity) dataset [1] consisting of videos where people carry out the following seven activities: cooking, setting the table, eating, cleaning, washing up and working. The videos were recorded by three Kinect cameras in the kitchen area of the Mobile Mii platform. The DAHLIA dataset is public and can be downloaded at this address: www-mobilemii.cea.fr
The challenges
The main difficulty related to the recognition of activities is the great variability in carrying out the same activity. For example, “cooking” is composed of a multitude of sub-actions that can be performed in a different order from one person to another. It is also possible to confuse certain activities if the time window of observation is not large enough. It is also difficult to strictly delimit the beginning and end of an activity. Finally, we would like the technology developed to be independent from the camera’s point of view in order to be functional in any flat.
Proposed solution
To deal with this problem, the CEA has implemented the DOHT algorithm [2], which enables the activity of people in the scene to be recognised on the basis of their movements. The algorithm requires as input the estimation of the person’s 3D pose at each moment. The DOHT then estimates a confidence score for each class of activity according to the trajectories of the skeleton joints observed over a certain time window.
The recognition rate of the DOHT on the DAHLIA dataset is 70%.
[1] The DAily Home LIfe Activity Dataset: A High Semantic Activity Dataset for Online Recognition, G. Vaquette, A. Orcesi, L. Lucat, C. Achard, in IEEE Automatic Face and Gesture Recognition (FG), 2017
[2] Robust information fusion in the DOHT paradigm for real time action detection, G. Vaquette, C. Achard and L. Lucat, in Journal of Real-Time Image Processing, 2016
Objective
Learning to detect events in videos consists in finding starting and ending frames of the events of interest and, when possible, localize them in the image. This task is particularly useful for applications such as event retrieval in large amounts of videos, video summarization or real-time monitoring.
Challenge
The characterization of events can come from both spatial (e.g. size, appearance) and temporal (e.g. motion) information.
When training data is sparse for the events of interest or when it is difficult to collect data with the variability of appearance of such events, learning to detect such events becomes very challenging.
Our Proposal for Violent Event Detection
• A novel and compact feature discriminating structuredness of observed motions.
• A feature embedded in a weakly supervised learning framework.
• An efficient method for real-time violence detection in on-board video-surveillance.
• Ability of the learned model to generalize training data for varied contexts.
• A new dataset representative of the targeted application for extensive evaluation.
RIMOC, a feature to discriminate unstructured motions: Application to violence detection for video-surveillance. P.C. Ribeiro, R. Audigier, Q.C. Pham. In Computer Vision and Image Understanding, Elsevier, 2016, 144, pp.121-143.
Abstract: In video-surveillance, violent event detection is of utmost interest. Although action recognition has been well studied in computer vision, literature for violence detection in video is far sparser, and even more for surveillance applications. As aggressive events are difficult to define due to their variability and often need high-level interpretation, we decided to first try to characterize what is frequently present in video with violent human behaviors, at a low level: jerky and unstructured motion. Thus, a novel problem-specific Rotation-Invariant feature modeling MOtion Coherence (RIMOC) was proposed, in order to capture its structure and discriminate the unstructured motions. It is based on the eigenvalues obtained from the second-order statistics of the Histograms of Optical Flow vectors from consecutive temporal instants, locally and densely computed, and further embedded into a spheric Riemannian manifold. The proposed RIMOC feature is used to learn statistical models of normal coherent motions in a weakly supervised manner. A multi-scale scheme applied on an inference-based method allows the events with erratic motion to be detected in space and time, as good candidates of aggressive events. We experimentally show that the proposed method produces results comparable to a state-of-the-art supervised approach, with added simplicity in training and computation. Thanks to the compactness of the feature, real-time computation is achieved in learning as well as in detection phase. Extensive experimental tests on more than 18 h of video are provided in different in-lab and real contexts, such as railway cars equipped with on-board cameras.
Keywords: Violence detection; Aggression detection; Violent event detection; Unstructured motion; Abnormality detection; Video-surveillance
The problem here is to understand what is the behaviour of a specific crowd. By crowd behaviour we mean specific motion pattern of the crowd such as bottleneck, panic movement, etc.
One can ask if it is necessary to detect and track each person of a crowd to understand the global crowd behaviour. This work try to answer this question. In [1], we proposed mid-level visual descriptors to learn crowd movements and recognize classes of behaviour.

Mid-level visual features for classifying crowd behaviour were presented in [1].
In CrowdCNN [2], we train a 2D+t convolutionnal neural network to classify video clip of crowd among 11 types of crowd behaviour. These types of behaviour cover either static calm crowd or agitated one, crowd motion really structured or one the contrary completely erretic motion within the crowd, etc. From this classification, learnt features can be extracted to have a crowd representation that can be further used for specific event detection and so on.
To train and evaluate CrowdCNN, a new dataset, Crowd-11, annotated with 11 classes of behaviour patterns is proposed.
Crowd-11 dataset available upon request at crowd11-dataset@cea.fr

[1] Crowd behavior analysis using local mid-level visual descriptors, H. Fradi, B. Luvison, Q.C. Pham, in IEEE Transactions Transactions on Circuits and Systems for Video Technology (TCSVT), special issue on “Group and Crowd Behavior Analysis for Intelligent Multi-camera Video Surveillance”, 2016.
[2] Crowd-11: A Dataset for Fine Grained Crowd Behaviour Analysis, C. Dupont, L. Tobias, B. Luvison, in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) 2017
Illustration of meta-learning setup [1]: After several episodes of meta-training to distinguish 5 classes with 1 image per class, the model learns the target task during meta-test.
Many tasks of computer vision (object detection, image classification, person and activity recognition) are successfully solved by deep learning. The main drawback of these approaches based on deep neural networks is their need for large amounts of labeled data during a supervised training. On the one hand, manual annotation of data is a tedious, expensive and possibly complex task (experts can be thus necessary). On the other hand, this data can be rare or difficult to collect. Consequently, methods to learn from few examples are necessary.
Two main strategies can be cited. The first one consists in learning generic features from a single global task and reuse them to solve the target task. The second one is meta-learning which consists in "learning to learn" with few data from multiple elementary tasks, in order to be able to quickly adapt to the target task.
In a recent work [2], we show how the recent advances in meta-learning theory can be used in practice both to better understand the behavior of popular meta-learning algorithms and to improve their generalization capacity. This latter is achieved by integrating the theoretical assumptions ensuring efficient meta-learning in the form of regularization terms into several popular meta-learning algorithms for which we provide a large study of their behavior on classic few-shot classification benchmarks.
[1] Optimization as a Model for Few-Shot Learning. Sachin Ravi, Hugo Larochelle. ICLR 2017.
[2] Putting Theory to Work: From Learning Bounds to Meta-Learning Algorithms. Quentin Bouniot, Ievgen Redko, Romaric Audigier, Angélique Loesch, Amaury Habrard. Accepted at NeurIPS 2020 Workshop on Meta-Learning, Dec. 2020.
[3] Human-level concept learning through probabilistic program induction. Lake, B. M., Salakhutdinov, R., and Tenenbaum, J. B. (2015), Science, 350(6266), 1332-1338.

Dataset Omniglot [3]: Comment apprendre à reconnaître de nouveaux alphabets à partir d'un seul exemple par caractère?
Contrary to conventional supervised approaches, methods based on One-Class Learning learn the representation of the normal class without any examples of anomaly of interest. The main challenge is to find a transformation that would lead to a compact distribution of the representations of most normal samples in the new space while projecting unseen anomalous examples far enough from the normal class.
As a result of research work conducted in the lab, Patch Distribution Modeling method (PaDiM) [1] has been proposed to detect and localize anomaly in images. This simple yet effective method outperforms the current state of the art on popular academic datasets for anomaly detection and localization.
[1] PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization. Thomas Defard, Aleksandr Setkov, Angélique Loesch, Romaric Audigier, Accepted at ICPR 2020 Workshop on Industrial Machine Learning, Jan. 2021.

Example of anomaly localization in images from MVTec AD dataset

Example of self-supervised task:
future frames prediction
Self-supervised approach based on contrastive predictive coding with fully convolutional architecture
Self-supervised learning aims at solving a pre-training task without explicit label supervision. Instead, supervision signals are extracted from the data itself by predicting a part of the input signal from the observable parts. Self-supervised learning are efficient techniques to reduce the amount of labeled data needed to solve problems with supervised learning methods. In this line of research, we study the use of self-supervised learning for video analytics tasks such as action and activity recognition where the cost of annotation is difficult to reduce.
The challenges are mainly related to the complex structure of video signals where the notions of object, motion, space and time interact in a subtle way. The self-supervised task need to take them into account to be efficient. In addition, current self-supervised pre-training methods require a large computing and memory capacity. This makes difficult to apply them at low cost.
We propose to tackle these challenges by improving pre-training methods based on feature frame representation prediction in several ways:
Use several input modalities : image, optical flow
Use fully convolutional architecture to take into account spatial dimension when predicting the future in the time dimension
Reduce the number of negative examples need by the contrastive estimation loss by means of data augmentation
Our current results are promising and we are continuing study the self-supervised learning and representation learning algorithm in more general and formal way.


Results on UCF-101 and HMDB51 datasets according to different inputs modalities. Our method exceeds the state of the art.
Learning representations beforehand gives better results when transferred to a database with few examples.
[1] G. Lorre, J. Rabarisoa, A. Orcesi, S. Ainouz, S. Canu, Temporal Contrastive Pretraining for Video Action Recognition, IEEE Winter Conference on Applications of Computer Vision (WACV) 2020
[2] G. Lorre, J. Rabarisoa, A. Orcesi, S. Ainouz, S. Canu, Contrastive Predictive Coding for Video Representation Learning, Workshop Self-Supervised Learning, ICML, 2019

Automatically re-identifying people viewed by cameras is a key functionality for video surveillance applications. It consists in retrieving occurrences of a person (represented by a query) from a set of images (gallery). Despite the many studies on this topic in the past few years, modeling human appearance remains a challenge. Indeed, re-identification models have to discriminate distinct people (in spite of their possible similarity) while being robust against the high variability of their visual appearance (caused by their posture, lighting conditions, camera viewpoint, sensitivity and resolution, ...). Besides, partial occlusion and alignment errors on the detected people have to be coped with. Even if deep supervised learning methods have been greatly improving re-identification performances on some academic datasets, difficulties remain for real implementations in operational environments. Indeed, a model trained on a specific dataset (source) usually does not perform well if applied on other datasets (targets) as it is. Unsupervised Domain Adaptation (UDA) is an interesting research direction for this challenge as it avoids a costly annotation of the target data. Pseudo-labeling methods achieve the best results in UDA-based re-identification. They incrementally learn with identity pseudo-labels which are initialized by clustering features in the source identity encoder space.
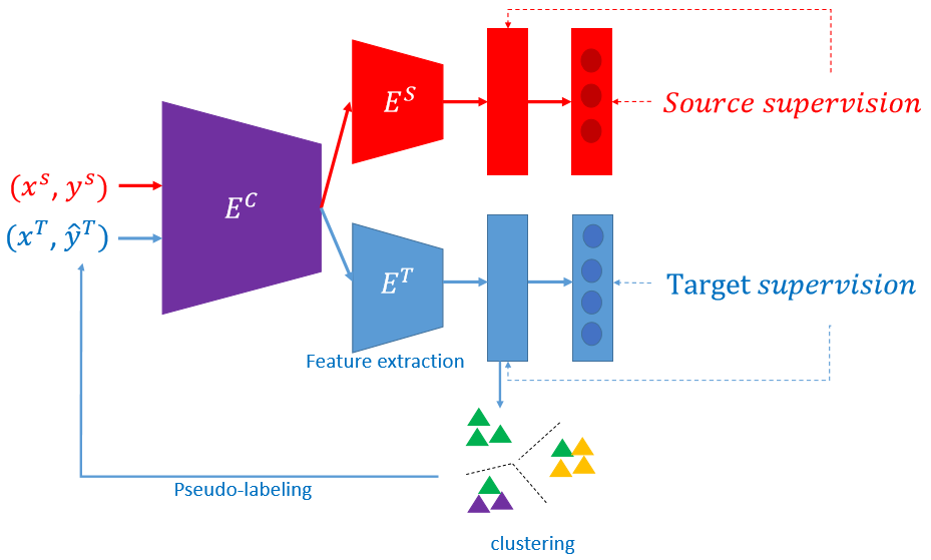
In order to improve robustness against erroneous pseudo-labels, we advocate the exploitation of both labeled source data and pseudo-labeled target data during all training iterations. To support our guideline, we introduce a framework [1] that allows adaptability to the target domain while ensuring robustness to noisy pseudo-labels. Our method is simple enough to be easily combined with existing pseudo-labeling UDA approaches. Our approach reaches state-of-the-art performance when evaluated on commonly used datasets, Market-1501 and DukeMTMC-reID, and outperforms the state of the art when targeting the bigger and more challenging dataset MSMT.
HyPASS
Pseudo-labeling approaches have proven to be effective for UDA re-ID. However, the effectiveness of these approaches heavily depends on the choice of some hyperparameters (HP) that affect the generation of pseudo-labels by clustering. The lack of annotation in the domain of interest makes this choice non-trivial. Current approaches simply reuse the same empirical value for all adaptation tasks and regardless of the target data representation that changes through pseudo-labeling training phases. As this simplistic choice may limit their performance, we aim at addressing this issue. We propose new theoretical grounds on HP selection for clustering UDA re-ID as well as method of automatic and cyclic HP tuning for pseudo-labeling UDA clustering: HyPASS [2]. HyPASS consists in incorporating two modules in pseudo-labeling methods: (i) HP selection based on a labeled source validation set and (ii) conditional domain alignment of feature discriminativeness to improve HP selection based on source samples. Experiments on commonly used person re-ID and vehicle re-ID datasets show that our proposed HyPASS consistently improves the best state-of-the-art methods in re-ID compared to the commonly used empirical HP setting.
[1] Unsupervised Domain Adaptation for Person Re-Identification through Source-guided Pseudo Labeling, Dubourvieux F., Audigier R., Loesch A., Ainouz S., Canu S., International Conference on Pattern Recognition (ICPR) 2020
[2] Improving Unsupervised Domain Adaptive Re-Identification Via Source-Guided Selection of Pseudo-Labeling Hyperparameters, F. Dubourvieux, A. Loesch, R. Audigier, S. Ainouz and S. Canu, IEEE Access, vol. 9, pp. 149780-149795, 2021.
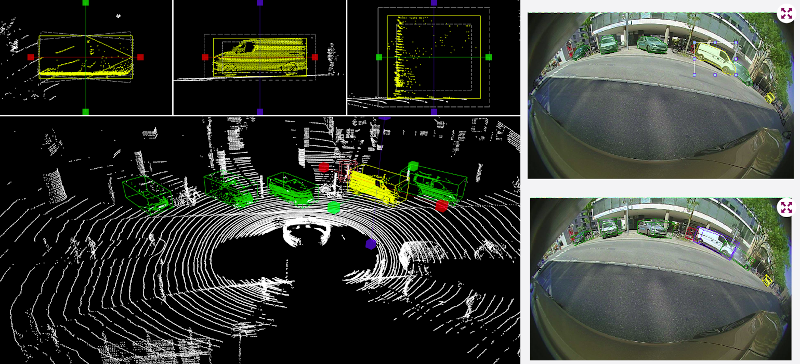
As LiDAR point clouds are rich in spatial information and geometry, they are also more difficult to manipulate than classic RGB images. A semi-automatic method has been proposed and developed to automatically annotate cuboids in point clouds from 2d annotations.

Manual annotation of objects of interest in an image is a very tedious and costly task, especially for fine-grained annotation (pixel-by-pixel level or polygonal). We have developed new algorithms for interactive instance segmentation requiring very little human effort (2 clicks).

Object annotation with bounding boxes can be performed by a single click in the middle of the objects, thanks to deep neural networks.
Automatic propagation of 3D bounding boxes in LIDAR point clouds

The Deep Learning revolution has made possible perception tasks that were unthinkable merely 10 years ago, and continues to extend to more and more tasks and responsibility. Most perception methods, however, are still based on supervised or semi-supervised learning and require a significant amount of annotated data. It is therefore crucial for manufacturers who use or market these systems to build up relevant databases to train them, assess them and validate their capacities.
We address this challenge by designing PIXANO (Pixel Annotation), an open source solution for efficient large-scale web annotation of images and videos. The tool offers a wide range of labels (bounding box, polygon, cuboid, pixel mask) integrated into open, modular, reusable and customizable web components. The components are powered by artificial intelligence that helps humans in their annotation task and reduces the number of clicks required to create labels.
The relevance of this solution has been validated by major players in the industry, in particular the automotive industry, during partnerships and collaborative projects1 promoting the capitalization of the developments made. Through its modularity and its ability to integrate new customizable and intelligent components, PIXANO opens up wide prospects for the creation of solutions adapted to the needs of AI designers.
[1] In particular through the European projectH2020 CloudLSVA (https://cloud-lsva.eu/)
For a supervised learning task such as object detection in images and videos, labeled instances are time-consuming and thus expensive to obtain. However, it may not be the case for unlabeled instances and a large amount could thus be collected and made available. The key question thus becomes to choose the images (or frames) to annotate by an oracle, to learn a model that will have maximal performances on the task. Through the European project CPS4EU and industrial partnership, our work on active query selection is organized along three noteworthy lines of research:
(i) the analysis of model uncertainty combined with semi-supervised techniques,
(ii) the selection of under-represented classes
(iii) the modeling of data diversity to guarantee the coverage of a database.
Active Learning contribution to object detection training (left) and unsupervised data context clustering (right)
CPS4EU: The vision of CPS4EU is to foster innovation that will maintain and strengthen European leadership in key sectors of the economy by creating synergies between SMEs, large companies and large research organizations operating in the CPS (Cyber Physical Systems) sector. https://cps4eu.eu/

Reinforcement learning is a field of machine learning where a software agent learns to make decision by interectacting with its environment and by maximining the cummulative reward it receives. Reinforcement learning has been applied successfully in different fields such as gaming, energy mqnagement, advertising and robotics.
We have several ongoing research topic on reinforcement learning. We work on how to learn efficient representation for high dimensional input state to make reinforcement agent training more stable. Developing explainable and interpretable agents is also essential to deploy them in critical application such as autonomous driving. Simulators play an important role while training reinforcement learning agents nowadays. Being able to transfer agent trained with a simulator to real world environment becomes a major challenge.
Person re-identification (re-ID) is a key problem in smart supervision of camera networks. Over the past years, models using deep learning have become state-of-the-art. However, it has been shown that deep neural networks are flawed with adversarial examples, i.e., human-imperceptible perturbations. Extensively studied for the task of image closed-set classification, this problem can also appear in the case of open-set retrieval tasks. Indeed, recent work has shown that we can also generate adversarial examples for metric learning systems such as re-ID ones. These models remain vulnerable: when faced with adversarial examples, they fail to correctly recognize a person, which represents a security breach. These attacks are all the more dangerous as they are impossible to detect for a human operator. Attacking a metric consists in altering the distances between the feature of an attacked image and those of reference images, also called "guides".
We show that attack feasibility depends on availability of such guides. So, to cope with two extreme situations of no availability and full availability of guides, we propose two novel attacks for metric embedding problems [3]: the Self Metric Attack (SMA) and the Furthest Negative Attack (FNA). As shown in the figure below (performance of an attacked model according to the perturbation size), FNA outperforms the state of the art (cf. illustration above for its principle). Moreover, we propose an efficient extension of adversarial training protocol adapted to metric learning as a defense [3] that increases the robustness of re-ID models.
The open source code is available on our github.
[1] Open Set Adversarial Examples. Zhedong Zheng et al. In arXiv:1809.02681
[2] Metric Attack and Defense for Person Re-identification. Bai S. et al. 2019. In arXiv:1901.10650
[3] Vulnerability of Person Re-Identification Models to Metric Adversarial Attacks, Bouniot Q., Audigier R. and Loesch A., Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) 2020
Sinkhorn Adversarial Training (SAT):
Optimal Transport as a Defense Against Adversarial Attacks
The most effective methods to defend against adversarial attacks trains on generated adversarial examples to learn their distribution. Previous work aimed to align original and adversarial image representations in the same way as domain adaptation to improve robustness.
In this work [4], the analogy of domain adaptation is taken a step further by exploiting optimal transport theory. We propose to use a loss between distributions that faithfully reflect the ground distance. This leads to SAT (Sinkhorn Adversarial Training), a more robust defense against adversarial attacks. Then, we propose to quantify more precisely the robustness of a model to adversarial attacks over a wide range of perturbation sizes using a different metric, the Area Under the Accuracy Curve (AUAC). We perform extensive experiments on both CIFAR-10 and CIFAR-100 datasets and show that our defense is globally more robust than the state-of-the-art.
The open source code is available on our github.
[4] Optimal Transport as a Defense Against Adversarial Attacks, Quentin Bouniot, Romaric Audigier, Angélique Loesch, The IEEE 25th International Conference on Pattern Recognition (ICPR'20), January 2021.