
Nous menons des travaux sur les technologies de description et de compréhension des contenus multimédia (image, texte, parole, vidéo) et multilingues, en particulier à grande échelle.
Nous développons des algorithmes efficaces et robustes pour l’extraction de contenus multimédia, leur classification et leur analyse sémantique. Nous proposons également des méthodes et des outils pour la construction, la formalisation et l’organisation des ressources et connaissances nécessaires au fonctionnement de ces algorithmes.
Nous cherchons tout particulièrement à croiser les informations textuelles et visuelles pour définir de meilleures représentations multimodales. Cette fusion de données hétérogènes permet une interprétation de scènes ou de documents plus proche des besoins des utilisateurs.
Les applications de ces méthodes sont les moteurs de recherche, agents conversationnels, rapports synthétiques de veille, etc.
Thèmes de recherche
Analyse linguistique multilingue

Analyseur linguistique multilingue
LIMA est un analyseur linguistique supportant 60 langues, distribué sous double licence libre et propriétaire.
Extraction et synthèse d’information – adaptation au domaine

Analyse linguistique adaptée au domaine
CLIMA, le configurateur de LIMA, permet de modifier les fichiers de configuration et les ressources linguistiques de LIMA pour analyser les documents d’un nouveau domaine spécifique

Détection supervisée d’événements
Filtrer les termes d’un domaine spécialisé et identifier les liens
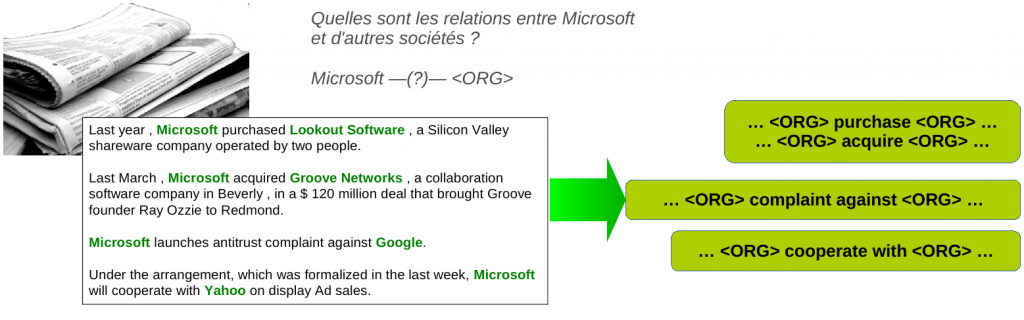
Extraction non supervisée de relations
Les travaux menés dans le cadre de l’extraction d’information ouverte ont montré la possibilité d’extraire des relations de façon générique à partir d’un corpus et de caractériser leur type a posteriori par le biais de processus de regroupement.

Synthèse d’information
Il est possible de résumer plusieurs documents simultanément par extraction, en y intégrant une dimension de mise à jour temporelle.
Apprentissage frugal
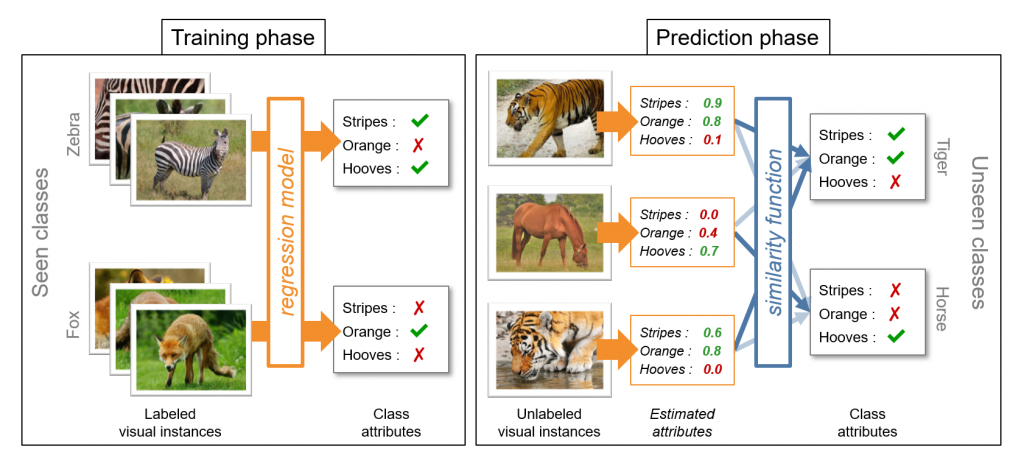
Apprentissage sans exemple visuel
Le zero-shot learning permet de reconnaître des objets sans exemple annoté d’apprentissage, grâce à une description sémantique (textuelle) de la classe.

Apprentissage incrémental
Mettre à jour les modèles d’apprentissage avec de nouvelles données issus de données, en limitant le coût en temps de calcul et le besoin mémoire.
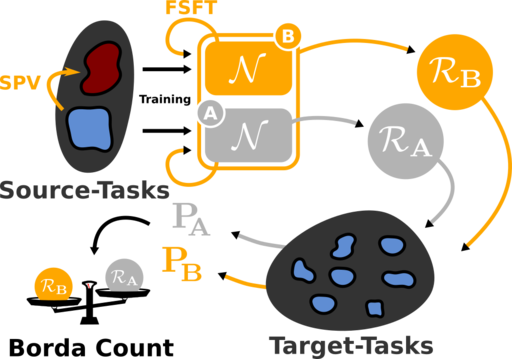
Transfert d’apprentissage rapide et efficace
Le transfert d’apprentissage permet de déployer les technologies de reconnaissance d’objets sur un cas d’usage particulier. La combinaison de plusieurs méthodes minimise ce coût d’adaptation.
La technologie Semfeat permet de classifier des images selon plusieurs dizaines de milliers de classes, tout en étant rapide à mettre en œuvre et à moindre coût calculatoire. Évolutive, de nouvelles classes peuvent être ajoutées par l’utilisateur.
Au cœur des technologies de transfert, des réseaux « universels » permettent de s’adapter à un grand nombre de cas d’usage en maintenant de bonnes performances
Exploitation conjointe du texte et de l’image

Entity Linking multimédia
Nous désambiguïsons des entités (personnes, lieux, organisations…) parmi des millions de possibilités. Quand le contexte textuel est limité (tweets), nous intégrons l’information visuelle pour améliorer les performances.

Rapprochement cross-modal
Décrire les modalités textuelles et visuelles de manière homogène permet de naturellement rapprocher le contenu des images et des documents écrits. Il est même possible de définir une classe visuelle à partir de textes et réciproquement.
Applications centrées utilisateur

Protection de la vie privée
Les outils d’IA sont perçus comme intrusifs. Nous développons des outils pour permettre aux utilisateurs de gagner en contrôle sur leur vie privée