
Nos recherches au CEA LIST sont appliquées à la vision par ordinateur pour la compréhension automatique de scènes.
Nos travaux portent sur la conception de nouveaux modèles de perception basés sur l’apprentissage machine, notamment l’apprentissage profond, pour la reconnaissance visuelle dans les images et les vidéos, l’analyse des interactions, l’analyse du comportement des individus, des groupes et des foules, l’analyse et la caractérisation des données visuelles et l’annotation intelligente des données.
Thèmes de recherche
Reconnaissance visuelle
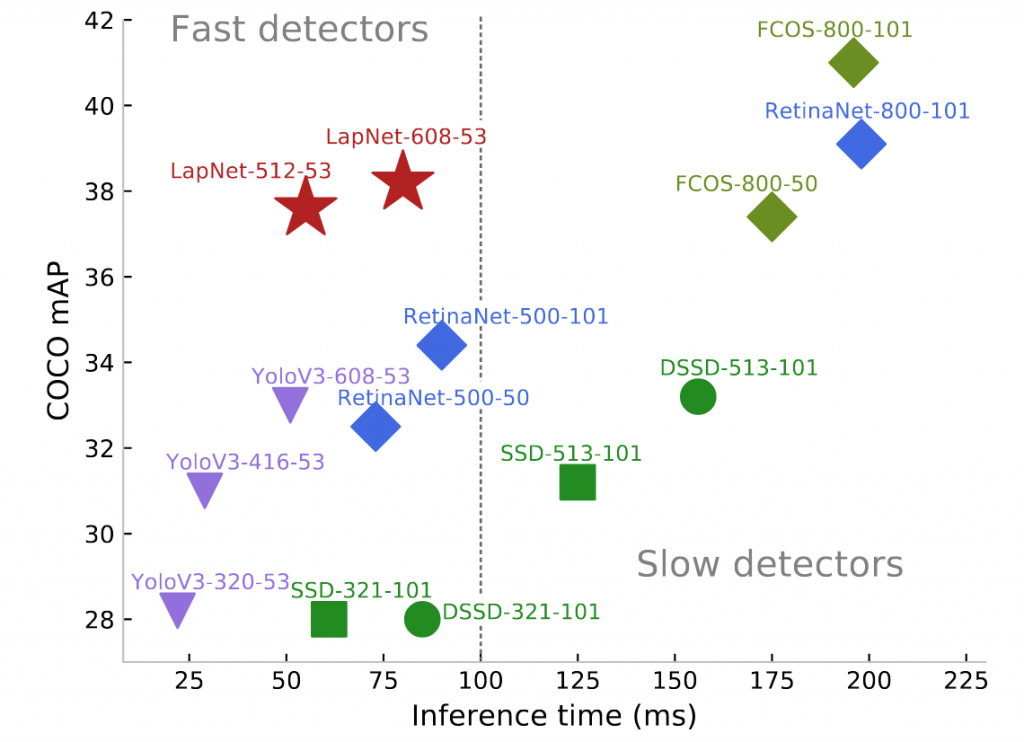
Détection d’objets rapide et robuste
Lapnet : détecteur d’objets une-passe au rapport performance/complexité à l’état de l’art

Reconnaissance fine d’objets
Apprentissage de représentations commune couleur et contour à partir de données réelles et synthétiues

Réseaux de neurones convolutifs multi-tâches pour la détection d’objets et la segmentation sémantique
Deep MANTA (MAny TASk) et Single-Shot Deep MANTA

Estimation de pose humaines 3D à partir d’images 2D
PandaNet: réseau de neurones single-shot basé ancres pour la détection de personnes, l’estimation de leurs poses 2D et 3D

Modélisation de l’apparence pour la ré-identification
Apprentissage de bout-end-bout de réseaux de neurones pour la détection et la ré-identification simultanées de personnes

Reconnaissance d’attributs sémantiques
Framework unifié pour la segmentation d’instances et la segmentation d’attributs sémantiques
Analyse de comportements
Suivi multi-objets temps réel
Suivre tous les objets observés dans une camera ou un réseau de caméras en combinant détection d’objets et caractéristiques visuelles de ré-identification
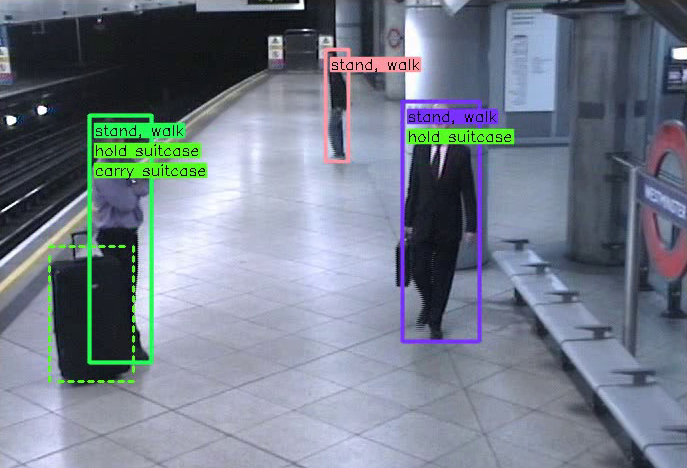
Détection d’interactions
Association automatique entre personne et objets dans une scène avec reconnaissance du type d’interaction
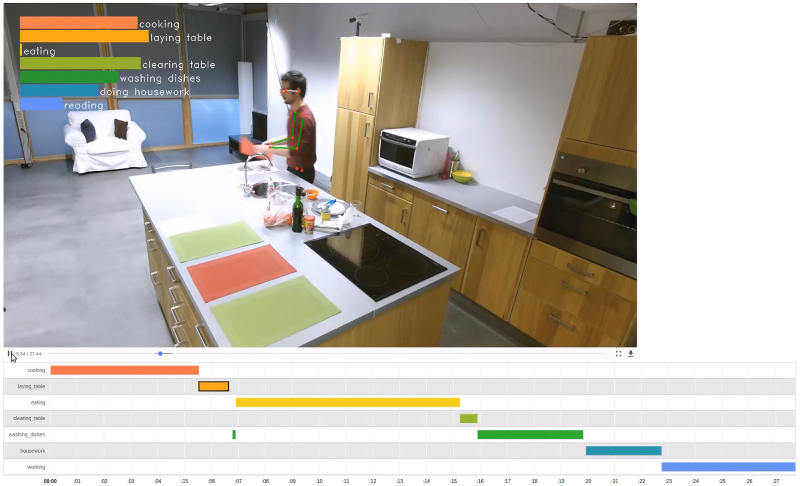
Reconnaissance d’activités
Reconnaissance des activités de la vie quotidienne par l’analyse des actions et personnes

Détection d’événements dans les vidéos
RIMOC: un descripteur de mouvements déstructurés pour la reconnaissance d’événements violents

Comportement de la foule
Crowd-11, un dataset de scènes de foules annotées avec 11 classes de comportement, et CrowdCNN un réseau de neurones convolutif profond pour la reconnaissance de ces 11 classes
Au-delà de l’apprentissage supervisé

Apprendre avec peu de données
Meta-learning: de la théorie à la pratique. Apprendre à apprendre avec peu de données à partir tâches élémentaires multiples afin de s’adapter rapidement à une nouvelle tâche, avec des capacités accrues de généralisation.
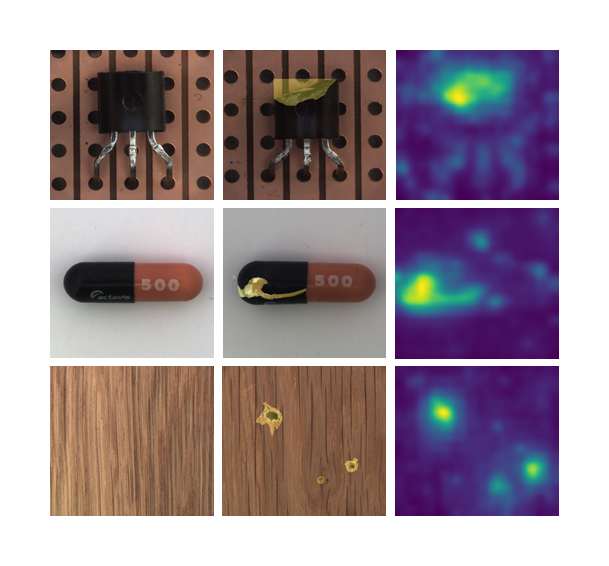
Apprentissage une-classe pour la détection d’anomalies
Patch Distribution Modeling method (PaDiM), une méthode simple et efficace pour détecter et localiser des anomalies dans les images
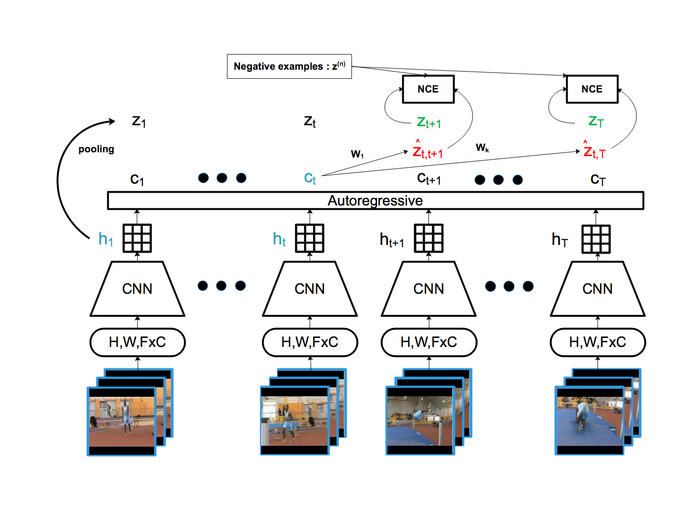
Apprentissage auto-supervisé de représentations d’image et de vidéo
Approche d’apprentissage auto-supervisé de représentations basée sur le Contrastive Predictive Coding (CPC) et une architecture de réseau de neurones convolutif
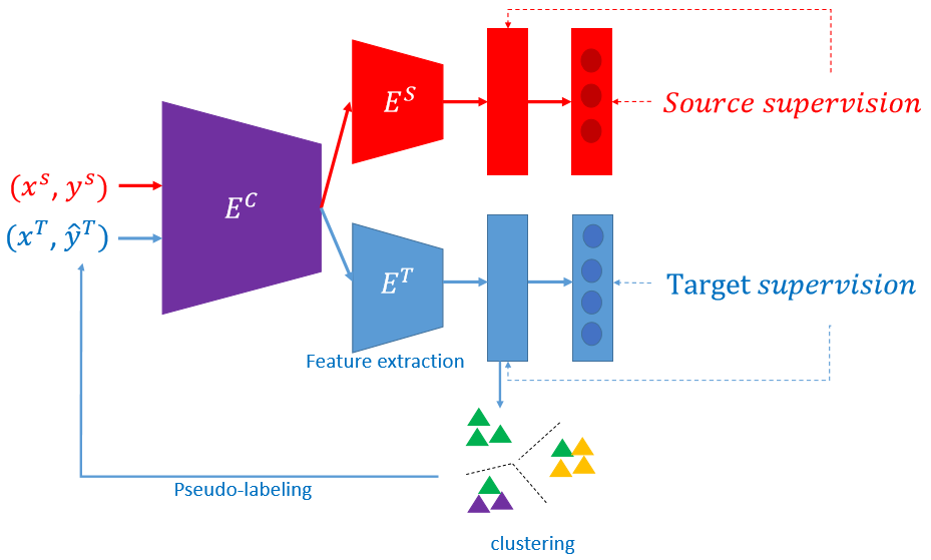
Adaptation de domaine pour la ré-identification de personnes
Approche non supervisée permettant l’adaptation au domaine cible tout en maintenant la robustesse au bruit des pseudo-labels
Annotation intelligente de données visuelles
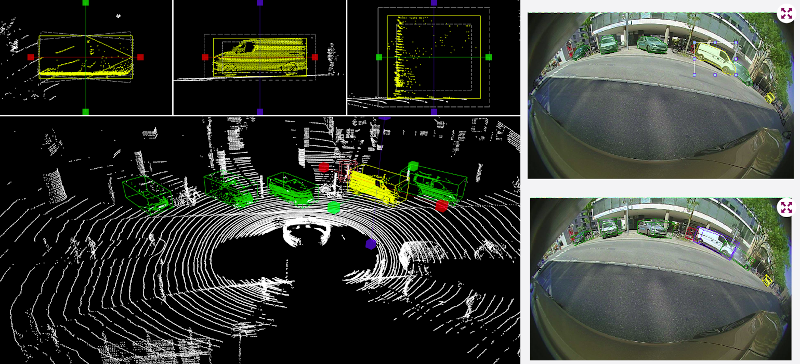
Annotation multimodale de données visuelles
Fusion de données 2D (images RGB issues de caméras) et 3D (nuages de points issus de LIDAR) pour l’annotation d’objets et de scènes 3D

Détection et segmentation interactives
Algorithmes d’apprentissage profond pour la segmentation d’instances dans l’image requérant très peu d’interactions d’utilisateur
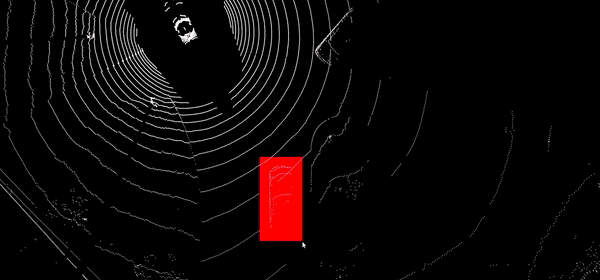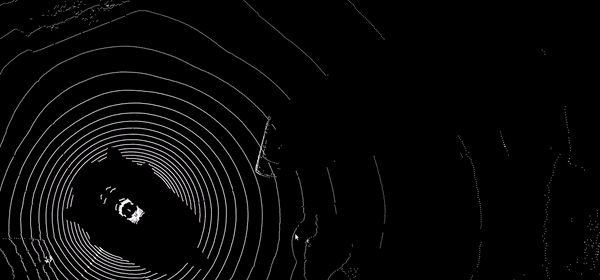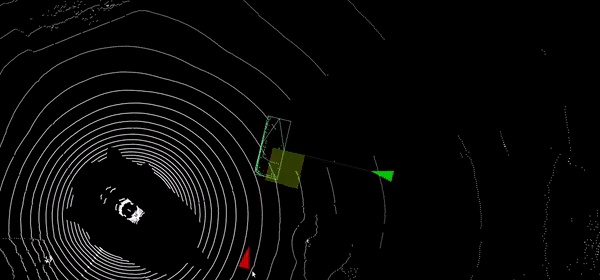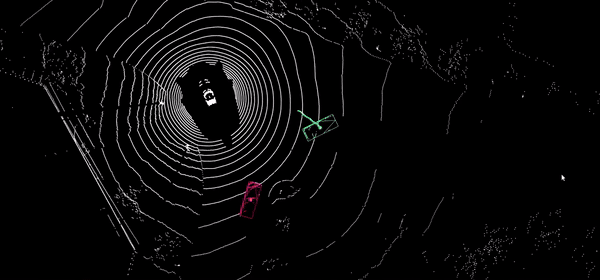
Propagation temporelle de labels
Propagation automatique d’annotations 2D et 3D dans les séquences temporelles par interpolation intelligente, suivi visuel dans les images et les nuages de points

PIXANO: un outil intelligent d’annotation pour la vision par ordinateur
Solution d’annotation efficace à grande échelle d’images et de vidéos, automatisée par l’IA, offrant un large éventail d’outils intégrés dans des composants web ouverts, modulaires, réutilisables et personnalisables

Apprentissage actif pour la détection d’objet et la segmentation d’image
Sélection active d’images pour l’apprentissage incrémental de modèles de détection et de segmentation, optimisant le rapport entre l’amélioration de performance et le nombre d’images annotées
Apprentissage par renforcement et modèles de perception

Apprentissage par renforcement pour la navigation autonome
Apprentissage de représentation de données en grande dimension pour entraîner par renforcement des agents à conduire
IA de confiance
Attaques et défense adversaires en apprentissage profond de métriques
Self Metric Attack (SMA) et Furthest Negative Attack (FNA), deux nouvelles méthodes d’attaques adversaires de métriques, et une nouvelle version efficace de protocole d’entraînement adversaire pour l’apprentissage de métrique plus robuste