



















L’objectif de la reconnaissance fine d’objets est de pouvoir distinguer des classes d’objets très proches en apparence. Un cas d’usage typique est la reconnaissance de marque et modèle de véhicules. En plus de la forte similarité interclasse s’ajoute la difficulté de construire de grandes bases de données annotées pour l’apprentissage d’un modèle profond performant. Au CEA LIST, des algorithmes de reconnaissance fine basés sur des modèles 3D CAD ont été développés [1]. L’utilisation de ces données synthétiques permet de réduire considérablement le coût d’annotation: un seul modèle CAD permet de générer automatiquement un grand nombre d’images d’un véhicule sous plusieurs points de vue. Des stratégies d’adaptation de domaine par l’utilisation de caractéristiques communes entre les images naturelles et synthétiques permettent la généralisation du modèle pour l’appliquer à des cas d’usage réels.
[1] Deep edge-color invariant features for 2D/3D car fine-grained classification, F. Chabot, M. Chaouch, J. Rabarisoa, C. Teulière, T. Chateau, IEEE Intelligent Vehicle Conference (IV) 2017

Un réseau de neurones multi-tâches estime plusieurs types de prédictions en parallèle. Ce type d’architecture permet d’optimiser le temps de calcul lors de l’inférence par l’utilisation d’un seul modèle unifié. Ces réseaux apprennent également des caractéristiques visuelles communes entre différentes tâches, ce qui permet une meilleure généralisation du modèle. Au CEA LIST, le réseau multi-tâches Deep MANTA [1] a été développé dans le cadre de la détection d’objets 2D et 3D à partir d’une image monoculaire. Des travaux de recherche ont permis de rendre le réseau plus léger afin de le déployer dans des véhicules autonomes. D’autres tâches d’analyse de scène comme la segmentation sémantique et la prédiction de cartes de profondeur ont également été ajoutées au modèle pour obtenir une description complète de la scène.
[1] Deep MANTA: a coarse-to-fine many-task network for joint 2D and 3D vehicle analysis from monocular image, F. Chabot, M. Chaouch, J. Rabarisoa, C. Teulière, T. Chateau, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2017



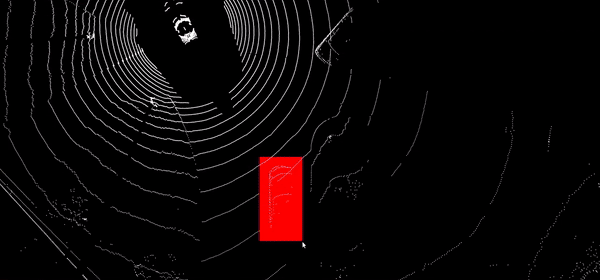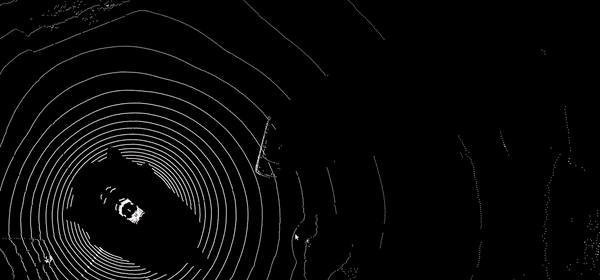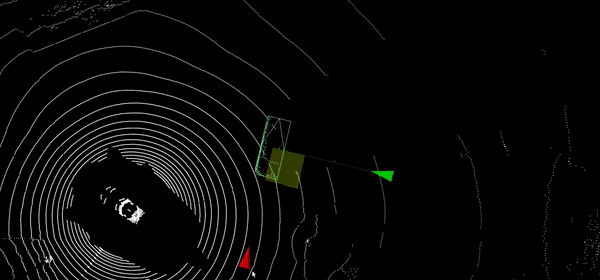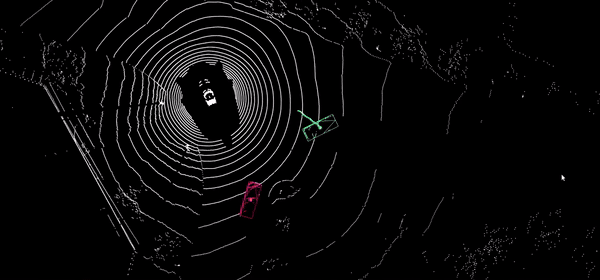
L’objectif de ces travaux est d’estimer la posture 3D de toutes les personnes observées dans une image RGB, en utilisant les technologies d’apprentissage profond.
Un tel défi met en jeu différents sujets de recherche tel que la détection afin de localiser les personne dans la scène, l’estimation du squelette 2D dans l'image, qui est intimement liée à l’estimation du squelette 3D, puisque l’un est la projection de l’autre, et le problème de généralisation pour transférer les informations 3D apprises à partir des bases d'images acquises dans des conditions de laboratoire vers des données dites « in the wild » plus représentatives de la réalité. Un dernier défi de taille est de pouvoir exploiter ce type de technologie en temps réel quelle que soit la complexité de la scène.
Nous avons développé PandaNet, une méthode qui résoud en même temps le problème de détection ainsi que celui d’estimation 2D et 3D. Pour cela, nous nous appuyons sur le détecteur Lapnet, également développé au laboratoire, qui est une méthode « single shot » avec une mécanique innovante dans la gestion des petits objets et des occultations. A partir de ce détecteur, nous avons ajouté l’estimation des postures 2D et 3D en tant que tâches additionnelles et nous avons aussi amélioré la gestion des occultations dans le cas particulier des personnes en prenant en compte la posture.
[1] PandaNet : Anchor-based single-shot multi-person 3d pose estimation , Benzine, A., F. Chabot, B. Luvison, Q. C. Pham et C. Achard, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020



La modélisation de l'apparence d'une personne peut servir à associer les différentes vues d'une même personne, autrement dit, à la réidentifier. La réidentification de personnes est une tâche essentielle de la vidéosurveillance et un domaine de recherche actif. C'est le coeur d'applications telles que la recherche automatisée de personnes ou le suivi multi-caméras de personnes. Malgré de nombreux travaux ces dernières années, la modélisation de l’apparence des personnes reste un défi. Elle doit pouvoir discriminer des personnes tout en étant robuste à la forte variabilité de leur apparence visuelle. Dans des scénarios réels, les images de personnes ne sont pas directement disponibles. Les résultats de réidentification dépendent donc de la qualité du détecteur de personnes utilisé pour les localiser. Par extension, la recherche de personnes est la problématique qui combine la détection et la réidentification dans un même cadre.
Au CEA LIST, nous proposons une nouvelle architecture CNN jointe [1] basée sur une architecture de détecteur dit single-shot (SSD). Le modèle proposé est entre 1,5 à 8 fois plus rapide que les modèles disjoints et est compétitif par rapport aux méthodes de l’état de l’art sur les jeux de données PRW [2] (cf. illustration ci-dessus) et CUHK-SYSU. De plus, les résultats montrent que les caractéristiques apprises à partir de datasets agrégés de détection, conduisent à de meilleures performances de réidentification dans le cas interdomaines, c'est-à-dire lorsque l'on n'a pas d'ensemble d'entrainement du dataset cible.
Ci-dessous, une vidéo illustrant un de nos modèles de réidentification de personnes avec comme images requêtes et comme galerie des images issues du dataset Visdrone [3]. Contrairement aux algorithmes de suivi, les résultats ne dépendent que de l'image courante, sans information des résultats des images précédentes.
[1] End-To-End Person Search Sequentially Trained On Aggregated Dataset, Loesch A., Rabarisoa J., Audigier R., IEEE International Conference on Image Processing (ICIP) 2019
[2] Person re-identification in the wild, Zheng, L., Zhang, H., Sun, S., Chandraker, M., Yang, Y., & Tian, Q., IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017
[3] Vision meets drones: A challenge, Zhu, P., Wen, L., Bian, X., Ling, H., & Hu, Q., arXiv preprint arXiv:1804.07437 2018

La reconnaissance en milieu non contraint d'attributs sémantiques de personnes est une tâche importante qui peut appuyer différents domaines d'application comme la vidéosurveillance ou l'analyse du comportement. De nombreuses méthodes s'intéressent à la segmentation sémantique des attributs vestimentaires et des parties du corps d'une seule personne (pour des applications plutôt orientées vers le domaine de la mode), cependant la reconnaissance en milieu non contraint implique la nécessité d'associer chaque attribut sémantique à une instance humaine comme contrainte supplémentaire (cf. illustrations ci-dessus avec des images du dataset CIHP [1]).
Au CEA-LIST, nous abordons la problématique en proposant un modèle de réseau de neurones profonds multi-tâches qui résout la tâche de segmentation sémantique des attributs et la tâche de segmentation d'instances de personnes de manière conjointe avec une architecture single-shot qui nous permet d'avoir un temps d'inférence indépendant du nombre de personnes détectées dans les images. Par ailleurs, notre méthode, de-bout-en-bout, n'a pas besoin d'une branche de raffinement ou de post-traitement supplémentaire pour obtenir les masques des personnes. Notre approche permet d'atteindre des résultats compétitifs avec l'état de l'art, tout en étant plus rapide.
Ci-dessous, une illustration de prédictions données par notre modèle de reconnaissance d'attributs sémantiques par individu sur deux images de validation du jeu de données CIHP.
[1] Instance-level human parsing via part grouping network, Gong, K., Liang, X., Li, Y., Chen, Y., Yang, M., & Lin, L., European Conference on Computer Vision (ECCV) 2018

L’objectif est de suivre simultanément des objets de différentes natures observés d’une ou plusieurs caméras dans l’image ou dans un repère 3D de l’environnement, le tout en temps réel.
Le suivi visuel est un procédé complexe qui met en œuvre de nombreuses technologies tel que la détection d'objets, la description de leur apparence visuelle, l’association spatiale et temporelle des observations et la calibrage des caméras. Parce que le suivi d'objets en temps réel est un processus markovien, la moindre erreur de localisation ou d'identification remet en cause l’intégrité et la cohérence du suivi des objets sur des intervalles de temps potentiellement longs. Il est donc nécessaire d'orchestrer l’ensemble des algorithmes de manière judicieuse afin de garantir un suivi cohérent le plus longtemps possible.
De manière analogue aux meilleures approches de l’état de l’art en suivi multi-objets, qui se basent sur des modules de détection et de ré-identification très robustes (Deep SORT, FairMOT), le laboratoire s’appuie également sur ses propres briques de détection et ré-identification auxquelles nous ajoutons des méthodes de raisonnement géométrique 3D que nous obtenons grâce à des informations fournies par l'estimation des squelettes des personnes et de calibrage des caméras.

L'objectif
L'objectif est de reconnaître toutes les interactions possibles entre les objets et les personnes et également entre personnes. Cette technologie permet d'analyser finement une scène et peut être appliquée dans le cadre de la vidéo surveillance pour détecter des bagarres ou des bagages abandonnés par exemple.
Les challenges
Il est nécessaire de détecter préalablement tous les objets d'une scène ce qui est un axe de recherche à part entière. Une fois que ces objets sont détectés, il faut pouvoir les associer avec le bon type d'interaction. Une interaction telle que "tenir" peut être réalisée avec une multitude de types d'objets différents. L'algorithme doit être capable de détecter l'interaction même s'il n'a jamais vu une personne tenir un certain type d'objet pendant son apprentissage : il doit être capable de généraliser l'interaction. De plus, les objets en interactions sont parfois occultés ou non visibles dans la scène. Dans ces cas, l'algorithme doit quand même être capable de reconnaître l'interaction juste avec l'apparence de la personne. Enfin, certaines interactions sémantiquement différentes sont proches visuellement telles que manger et boire ou tenir et soulever.
La solution proposée
La grande majorité des méthodes de l'état de l'art détectent préalablement tous les objets de la scène puis calculent une probabilité d'interaction entre tous les couples possibles. Le temps de calcul nécessaire pour traiter une image est donc quadratique et dépend du nombre d'objet dans la scène.
Le CEA LIST propose la solution CALIPSO (Classifying all interacting pairs in a single shot) [1] qui est une méthode à l'état de l'art, dite "en une passe", car elle estime les interactions en ne passant qu'une seule fois l'image dans le réseau de neurones. Pour se faire, les interactions sont estimées sur une grille dense d'ancres. Le point fort de CALIPSO est donc qu'il est rapide et indépendant du nombre d'objets dans l'image.
Le dataset utilisé
Nous utilisons le dataset V-COCO qui est constitué de 10 000 images et annoté avec une trentaine de verbes d'interaction.
[1] Classifying All Interacting Pairs in a Single Shot, S. Chafik, A. Orcesi, R. Audigier, B. Luvison, in IEEE Winter Conference on Applications of Computer Vision (WACV) 2020

Objectif
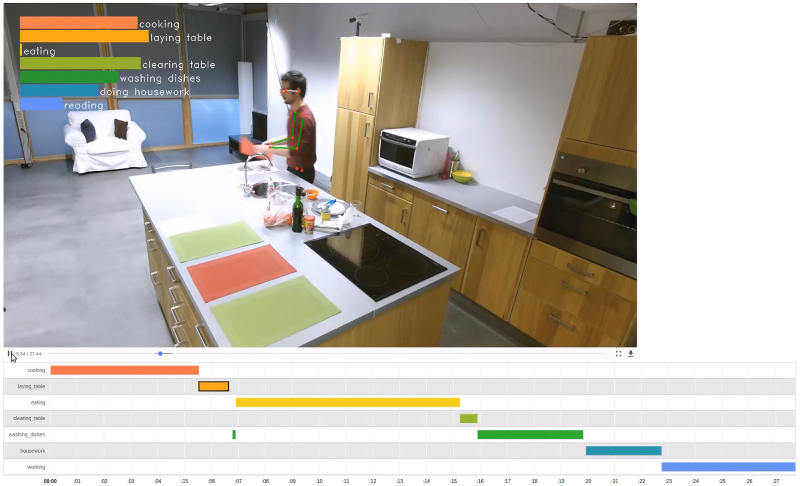
L'objectif est de reconnaître une activité et de la localiser dans le temps. Le CEA applique cette technologie dans le cadre du Smart Home où les cas d'usages sont diverses. En effet, la reconnaissance d'activités est utile à l'assistance des personnes âgées à domicile. Grâce à cette technologie, il est possible de repérer les activités quotidienne d'une personne. Le fait qu'elle ne fasse plus telle ou telle activité qui lui était habituelle peut dévoiler une perte d'autonomie. La reconnaissance d'activités est aussi utilisée dans un contexte de domotique pour améliorer le confort des habitants. Cela se traduit par une adaptation de l’ambiance lumineuse et sonore à l'activité de la personne.
La base de données utilisée
Le CEA a créé le dataset DAHLIA (Daily Home Life Activity) [1] composé de vidéos où des personnes réalisent les sept activités suivantes : cuisiner, mettre la table, manger, débarrasser, faire le ménage, faire la vaisselle et travailler. Les vidéos ont étés enregistrées par trois caméras Kinect dans l'espace cuisine de la plateforme Mobile Mii. Le dataset DAHLIA est publique et téléchargeable à cette adresse : www-mobilemii.cea.fr
Les challenges
La principale difficulté liée à la reconnaissance d'activités est la grande variabilité pour réaliser une même activité. Par exemple, "cuisiner" est composé d'une multitude de sous-actions qui peuvent être réalisées dans un ordre différent d'une personne à une autre. Il est aussi possible de confondre certaines activités si la fenêtre temporelle d'observation n'est pas assez grande. C'est également difficile de délimiter strictement le début et la fin d'une activité. Enfin, nous souhaitons que la technologie développée soit indépendante du point de vue de la caméra pour être fonctionnelle dans n'importe quel appartement.
Solution proposée
Pour traiter ce problème, le CEA a conçu l'algorithme DOHT [2] qui permet de reconnaître l'activité des personnes dans la scène à partir de leurs mouvements. L'algorithme a besoin en entrée de l'estimation de la pose 3D de la personne à chaque instant. Le DOHT estime ensuite un score de confiance sur chaque classe d'activité selon les trajectoires des articulations du squelette observées sur une certaine fenêtre temporelle.
Le taux de reconnaissance du DOHT sur le dataset DAHLIA est de 70%.
[1] The DAily Home LIfe Activity Dataset: A High Semantic Activity Dataset for Online Recognition, G. Vaquette, A. Orcesi, L. Lucat, C. Achard, in IEEE Automatic Face and Gesture Recognition (FG), 2017.
[2] Robust information fusion in the DOHT paradigm for real time action detection, G. Vaquette, C. Achard and L. Lucat, in Journal of Real-Time Image Processing, 2016
Objectifs
Apprendre à détecter des événements dans les vidéos consiste à trouver les images de début et fin qui délimitent les évènements d'intérêt dans le temps et, éventuellement, les localiser spatialement dans les images. Cette tâche est particulièrement utile pour les applications de recherche d'évènements dans de grandes quantités de vidéos, de résumé de vidéos, ou de surveillance en temps-réel.
Défis
La caractérisation des évènements peut venir aussi biend'informations spatiales (ex: taille, apparence) que temporelle (ex: mouvement). Lorsque les données d'entrainement sont rares pour les évènements d'intérêt ou qu'il n'est pas possible d'en obtenir un ensemble représentatif face à la variabilité de l'apparence de ces évènements, l'apprentissage devient difficile.
Notre proposition pour la détection d'évènements violents
• Un nouveau descripteur compact qui discrimine la structuration des mouvements observés.
• Un framework d'apprentissage faiblement supervisé utilisant les caractéristiques de ce descripteur.
• Une méthode efficace pour la détection de violence en temps réel pour la vidéosurveillance embarquée.
• Capacité du modèle appris à généraliser les données d'entrainement pour des contextes variés.
• Evaluation sur un nouveau dataset représentatif de l'application ciblée.
RIMOC, a feature to discriminate unstructured motions: Application to violence detection for video-surveillance. P.C. Ribeiro, R. Audigier, Q.C. Pham. In Computer Vision and Image Understanding, Elsevier, 2016, 144, pp.121-143.
Résumé: La détection d'évènements violents est d'importance capitale en vidéosurveillance. Bien que la reconnaissance d'actions soit un sujet assez étudié en vision par ordinateur, la littérature sur la détection de violence dans les vidéos est beaucoup plus éparse, et d'autant plus lorsqu'il s'agit d'applications de surveillance. Comme les évènements agressifs sont difficiles à définir de par leur variabilité et qu'ils nécessitent souvent un haut niveau d'interprétation, nous avons décidé d'essayer de caractériser tout d'abord ce qui est souvent présent dans les vidéos contenant des comportements violents, du point de vue du bas-niveau: des mouvements brusques et non structurés. Nous avons donc proposé un descripteur de caractéristiques Invariantes en Rotation modélisant la Cohérence du MOuvement (RIMOC) pour capturer la structure des mouvements normaux et les discriminer des mouvements erratiques spécifiques à notre problème. RIMOC est basé sur les valeurs propres des statistiques de second ordre sur les Histogrammes de Flot Optique, calculés localement de manière dense et plongés dans une variété Riemanienne sphérique. Demanière faiblement supervisée, des modèles statistiques de mouvements normaux cohérents sont appris à partir de ces caractéristiques RIMOC. Une inférence multi-échelles permet de détecter temporellement et spatialement les évènements comportant des mouvements erratiques, qui sont de bons candidats pour les évènements agressifs. Nous montrons expérimentalement que la méthode proposée produits des résultats comparables à l'état de l'art des approches supervisées, avec l'avantage d'être simple lors de l'entrainement et en termes de calcul en phase opérationnelle. Grâce à la compacité des caractéristiques, les calculs peuvent se faire en temps réel dans les phases d'entrainement et de détection. Des évaluations étendues sur plus de 18h de vidéos ont été faites sur différents contextes en labo et sur le terrain, comme par exemple à bord de voitures ferroviaires équipées de caméras.
Mots-clés: Détection de violence; détection d'agression; détection d'évènements violents; mouvements non-structurés; détection d'anomalie; vidéosurveillance.
Le problème abordé ici est de comprendre à partir d'une séquence vidéo quel est le comportement d’une foule. Par comportement de foule, nous signifions des catégories de mouvement ou de non-mouvement cohérents tel que des goulots d’étranglement, des mouvements de panique, etc
Une question que l’on peut se poser est: est-il nécessaire d’avoir détecté et suivi chaque individu dans la foule pour interpréter le comportement global de celle-ci ? Ces travaux cherchent à répondre à cette question.

Les travaux présentés dans [1] introduisent de nouveaux descripteurs de niveau sémantique intermédiaire pour la catégorisation des comportements de foule.
Dans CrowdCNN [2], la méthode proposé par le laboratoire, nous entraînons un réseau de neurones convolutif 2D+t pour classifier une vidéo selon 11 catégories de comportement de foule. Ces types de comportement couvrent les foules calmes et statiques, les foules agitées, les mouvements structurés ou au contraire complètement erratique, etc. A partir de cette classification, les primitives visuelles intermédiaires apprises peuvent être utilisées en tant que caractérisation de la foule et être ensuite utilisées pour la détection entre autres, d'événements spécifiques.
Pour entraîner et évaluer CrowdCNN, un dataset de scènes de foule annoté avec 11 classes de comportement, Crowd-11, été constitué.
La base de données Crowd-11 est disponible sur requête à l’adresse crowd11-dataset@cea.fr

[1] Crowd behavior analysis using local mid-level visual descriptors, H. Fradi, B. Luvison, Q.C. Pham, in IEEE Transactions Transactions on Circuits and Systems for Video Technology (TCSVT), special issue on “Group and Crowd Behavior Analysis for Intelligent Multi-camera Video Surveillance”, 2016.
[2] Crowd-11: A Dataset for Fine Grained Crowd Behaviour Analysis, C. Dupont, L. Tobias, B. Luvison, in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) 2017
Illustration du protocole de méta-apprentissage [1]: Après plusieurs épisodes de méta-entrainement pour distinguer 5 classes avec 1 image par classe, le modèle apprend la tâche cible durant le meta-test.
De nombreuses tâches en vision par ordinateur (détection d’objets, classification d’images, reconnaissance de personnes ou d’activités...) sont aujourd’hui réalisées avec succès par les méthodes d’apprentissage profond. L’inconvénient de ces approches basées réseaux de neurones profonds est que leur entrainement supervisé requiert de grandes quantités de données annotées. D’une part, l’annotation manuelle de données est une tâche longue, couteuse et parfois complexe (des experts sont alors nécessaires). D’autre part, ces données peuvent être rares ou difficiles à collecter. Il est alors nécessaire d’avoir des méthodes d’apprentissage qui se basent sur très peu d’exemples.
Deux stratégies principales se distinguent. L’une consiste à apprendre sur une seule tâche globale des caractéristiques suffisamment génériques pour résoudre la tâche élémentaire cible. L’autre stratégie est le paradigme de méta-apprentissage. Il consiste à "apprendre à apprendre" de multiples tâches élémentaires à partir de peu de données, pour ensuite pouvoir s’adapter facilement à la tâche élémentaire ciblée.
Dans de récents travaux [1], nous montrons comment les dernières avancées de la théorie du méta-apprentissage peuvent être utilisées en pratique pour, d'une part, mieux comprendre le comportement des algorithmes populaires de méta-apprentissage et, d'autre part, améliorer leur capacité de généralisation. A cette fin, nous proposons d'intégrer les hypothèses théoriques assurant un méta-apprentissage efficient sous la forme de termes de régularisation. Les améliorations sont évaluées sur les benchmarks connus pour la tâche de classification d'images à partir de peu d'exemples.
[1] Optimization as a Model for Few-Shot Learning. Sachin Ravi, Hugo Larochelle. ICLR 2017.
[2] Putting Theory to Work: From Learning Bounds to Meta-Learning Algorithms. Quentin Bouniot, Ievgen Redko, Romaric Audigier, Angélique Loesch, Amaury Habrard. Accepted at NeurIPS 2020 Workshop on Meta-Learning, Dec. 2020.
[3] Human-level concept learning through probabilistic program induction. Lake, B. M., Salakhutdinov, R., and Tenenbaum, J. B. (2015), Science, 350(6266), 1332-1338.

Dataset Omniglot [3]: Comment apprendre à reconnaître de nouveaux alphabets à partir d'un seul exemple par caractère?
Contrairement aux approches supervisées conventionnelles, les méthodes One-Class apprennent la représentation d’une classe dite « normale » sans aucun exemple des anomalies que l’on cherche à détecter. Le défi principal consiste à trouver un nouvel espace dans lequel les représentations de la plupart des exemples normaux aient une distribution compacte, de façon à ce que les représentations des exemples d’anomalies que l’on rencontrera soient suffisamment éloignés de la classe normale.
A la suite de travaux de recherche menés dans le laboratoire, la méthode Patch Distribution Modeling (PaDiM) [1] a été proposée dans le but de détecter et localiser les anomalies dans les images. Cette méthode simple, mais efficace, surpasse l’état de l’art actuel sur des jeux de données académiques pour la détection et localisation d’anomalies.
[1] PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization. Thomas Defard, Aleksandr Setkov, Angélique Loesch, Romaric Audigier, Accepted at ICPR 2020 Workshop on Industrial Machine Learning, Jan. 2021.

Exemple de localisation d’anomalie sur des images du jeu de données MVTec AD

Exemple de tâche auto-supervisée : la prédiction des images futures
Approche auto-supervisée proposée, basée sur la méthode CPC (contrastive predictive coding)
Malgré la grande quantité de données disponibles aujourd’hui, le coût de leur annotation peut limiter l’utilisation des méthodes d’apprentissage supervisées. Dans cet axe de recherche, nous étudions l’utilisation de l’apprentissage auto-supervisé qui permet d’exploiter les données non annotées. Le principe est de pré-apprendre une tâche auxiliaire dont l’objectif est de prédire une partie du signal d’entrée à partir des parties observables. Les représentations ainsi apprises sont ensuite utilisées pour initialiser un apprentissage supervisé qui nécessite moins de données labellisées.
Pour mettre en place notre méthode, nous nous intéressons à la tâche de reconnaissance d’actions dans des vidéos. Il s’agit de classifier des clips vidéos selon le type d’action. Les challenges de cette tâche sont principalement liés à la structure complexe des signaux vidéos où les notions d’objet, de mouvement, d’espace et de temps interagissent de façon subtile. De plus, les méthodes actuellement nécessitent une grande capacité de calcul et de mémoire pour leur apprentissage. Cela rend difficile leur application à moindre coût.
Nous proposons une amélioration des méthodes de pré-apprentissage basées sur la prédiction des représentations futures dans une vidéo sur plusieurs points:
l’utilisation de plusieurs modalités (image, flot optique)
l’utilisation d’une architecture complètement convolutif pour prendre en compte la dimension spatiale pour la tâche de prédiction du futur
l’amélioration de la gestion des exemples négatifs pour l’optimisation des fonctions coûts basées sur la comparaison entre exemples positifs et négatifs
Nos résultats pour le problème reconnaissances d’action dans une séquence vidéo sont prométteurs. Nous continuons de travailler sur l’apprentissage auto-supervisé de représentation pour d’autres applications.


Résultats sur les datasets UCF-101 et HMDB51 selon différentes modalités d’entrées. Notre méthode dépasse les résultats de l’état de l’art.
L’apprentissage préalable de représentations permet d’obtenir de meilleurs résultats quand il est transféré à une base de données avec peu d’exemples.
[1] G. Lorre, J. Rabarisoa, A. Orcesi, S. Ainouz, S. Canu, Temporal Contrastive Pretraining for Video Action Recognition, IEEE Winter Conference on Applications of Computer Vision (WACV) 2020
[2] G. Lorre, J. Rabarisoa, A. Orcesi, S. Ainouz, S. Canu, Contrastive Predictive Coding for Video Representation Learning, Workshop Self-Supervised Learning, ICML, 2019

La réidentification automatique de personnes est une fonctionnalité clé pour les applications de vidéoprotection. Elle consiste à retrouver les occurrences d'une personne dans un ensemble d'images. Malgré les nombreux travaux ces dernières années, la modélisation de l’apparence des personnes reste un défi. Elle doit pouvoir discriminer des personnes distinctes (malgré leurs éventuelles similitudes) tout en étant robuste face à la forte variabilité de leur apparence visuelle (due aux postures, aux points de vue, aux conditions d'illumination, à la sensibilité de la caméra, à sa résolution, ...). Elle doit également gérer les vues partiellement occultées et/ou mal centrées sur les personnes détectées. Si les méthodes d’apprentissage profond supervisé ont fortement amélioré les performances de réidentification sur certains jeux de données académiques, leur mise en œuvre opérationnelle demeure difficile. En effet, un modèle appris sur un jeu de données (source) est très souvent peu performant s’il est appliqué tel quel sur d’autres jeux de données (cibles). L'adaptation de domaine non supervisée (UDA) est un axe de recherche prometteur dans ce cas, car elle permet d'éviter une annotation coûteuse des données cibles. Les méthodes de pseudo-étiquetage obtiennent les meilleurs résultats en réidentification basée sur l’adaptation de domaine non supervisée. Elles apprennent progressivement avec des pseudo-étiquettes d'identité initialisées d’après l'espace de caractéristiques appris sur les données sources.
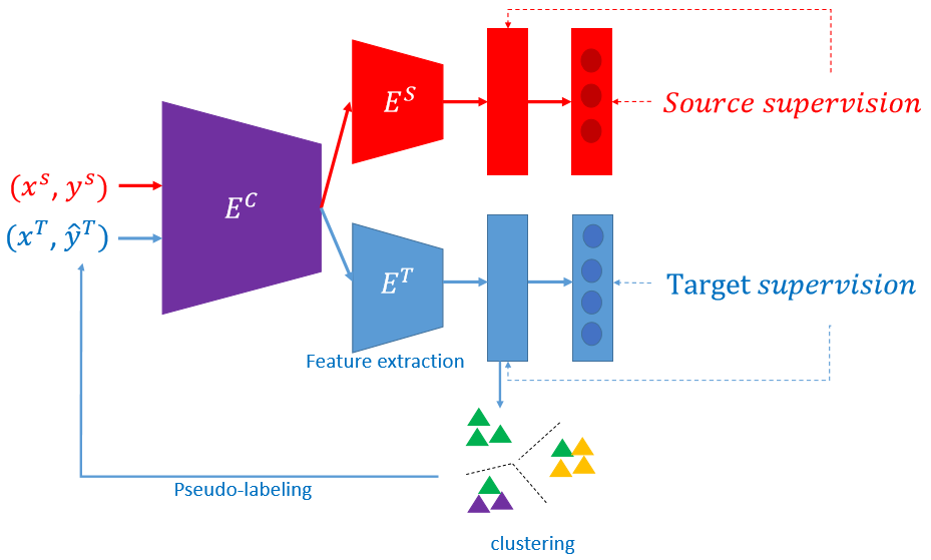
Afin d'améliorer la robustesse aux pseudo-étiquettes erronées, nous proposons l'exploitation à la fois des données sources étiquetées et des données cibles pseudo-étiquetées pendant toutes les itérations de l’entraînement du modèle de réidentification. Nous proposons une approche [1] permettant l'adaptabilité au domaine cible tout en assurant la robustesse aux pseudo-étiquettes bruitées. Notre méthode est suffisamment simple pour être facilement combinée avec les autres approches UDA de pseudo-étiquetage existantes. Notre approche atteint les performances de l’état de l’art lorsqu'elle est évaluée sur des datasets couramment utilisés, Market-1501 et DukeMTMC-reID, et surpasse l'état de l'art lorsqu'elle cible le dataset MSMT, plus grand et plus difficile.
HyPASS
Les approches de pseudo-étiquetage sont les plus efficaces pour la réidentification en UDA. Cependant, leur efficacité dépend fortement du choix de certains hyperparamètres (HP) qui affectent la génération des pseudo-étiquettes par clustering. L'absence d'annotation dans le domaine cible d'intérêt rend ce choix difficile. Les approches courante réutilisent simplement les mêmes valeurs empiriques quel que soit le domaine cible et les représentations qui changent durant les phases d'apprentissage. Ce choix simpliste peut cependant limiter les performances. Nous proposons un nouveau cadre théorique ainsi qu'une méthode automatique et cyclique pour la sélection de ces HP: HyPASS [2]. HyPASS consiste à incorporer deux modules dans les méthodes de pseudo-étiquetage: (i) une sélection des HP basée sur l'ensemble de validation étiqueté pour la source et (ii) un alignement conditionnel de domaines au niveau du pouvoir discriminant des représentations. Les expériences sur les jeux de données communément utilisés en réidentification de personnes et de véhicules montrent que notre méthode HyPASS améliore systématiquement les meilleures méthodes de l'état de l'art, comparé aux choix de HP qui sont faits empiriquement.
[1] Unsupervised Domain Adaptation for Person Re-Identification through Source-guided Pseudo Labeling, Dubourvieux F., Audigier R., Loesch A., Ainouz S., Canu S., International Conference on Pattern Recognition (ICPR) 2020
[2] Improving Unsupervised Domain Adaptive Re-Identification Via Source-Guided Selection of Pseudo-Labeling Hyperparameters, F. Dubourvieux, A. Loesch, R. Audigier, S. Ainouz and S. Canu, IEEE Access, vol. 9, pp. 149780-149795, 2021.
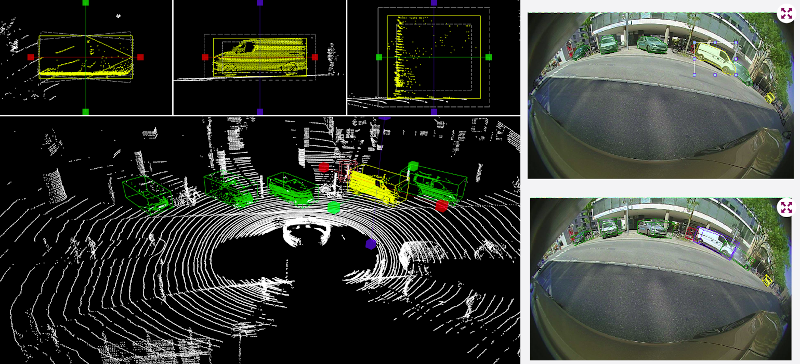
Très riches en information spatiale et notamment sur la géométrie des objets et de la scène, les nuages de points issus des capteurs LiDAR sont cependant plus difficiles à manipuler que les images RGB classiques. Nous avons développé une méthode semi-automatique permettant d'annoter automatiquement des cuboïdes dans le nuage de point à partir d'annotations 2d.

L'annotation manuelle des objets d'intérêt dans une image est une tâche très fastidieuse et coûteuse, en particulier pour l'annotation fine (niveau du pixel ou polygonal). Nous avons développé de nouveaux algorithmes pour la segmentation interactive par exemple, qui nécessite très peu d'interactions humaines (2 clics).

L'annotation des objets avec des boîtes englobantes peut être effectuée par un simple clic au milieu des objets, grâce à des réseaux neuronaux profonds.
Propagation automatique de boîtes englobantes 3D d'objets dans les nuages de points LIDAR

La révolution du Deep Learning a rendu possible des tâches de perception qui étaient impensables il y a 10 ans, et continue à évoluer pour répondre à de plus en plus des tâches et de responsabilité. La plupart des méthodes de perception sont cependant encore fondées sur l'apprentissage supervisé ou semi-supervisé et requièrent une quantité importante de données annotées. Il est donc crucial pour les industriels qui utilisent ou commercialisent ces systèmes de constituer des bases de données pertinentes pour les entraîner, les évaluer et valider leurs capacités.
L'expertise du CEA List lui a permis de relever ce défi en concevant PIXANO (Pixel Annotation), une solution open source pour l'annotation web efficace à grand échelle d'images et de vidéos. L'outil propose une large gamme d'étiquettes (boîte englobante, polygone, cuboîde, masque pixellique) intégrées dans des composants web ouverts, modulaires, réutilisables et personnalisables. Les composants sont alimentés par de l'intelligence artificielle qui vient assister l'humain dans sa tâche d'annotation et réduire le nombre de clics nécessaires à la création d'étiquettes.
La pertinence de cette solution a été validée par des acteurs majeurs de l'industrie, notamment automobile, au cours de partenariats et projets collaboratifs [1] favorisant la capitalisation des développements réalisés. Par sa modularité et sa capacité à intégrer de nouveaux composants personnalisables et intelligents, PIXANO ouvre de larges perspectives de création de solutions adaptées aux besoins des concepteurs d'IA.
[1] Notamment au sein du projet européen H2020 CloudLSVA (https://cloud-lsva.eu/)
Pour une tâche d'apprentissage supervisé telle que la détection d'objets dans des images et des vidéos, les instances annotées prennent du temps et sont donc coûteuses à obtenir. Cependant, cela peut ne pas être le cas pour les instances non étiquetées et une grande quantité pourrait ainsi être collectée et mise à disposition. La question clé est donc de choisir les images brutes (ou frames) à annoter par un oracle afin de maximiser les performances d'un modèle sur la tâche. À travers le projet européen CPS4EU et le partenariat industriel, nos travaux sur la sélection et l'apprentissage actif s'organisent selon trois axes de recherche:
(i) l'analyse de l'incertitude du modèle combinée à des techniques semi-supervisées,
(ii) la sélection des classes sous-représentées
(iii) la modélisation de la diversité des données pour garantir la couverture d'une base de données.
Contribution de la sélection active à l'apprentissage de modèle de détection (à gauche) et clustering non-supervisé du contexte des données (à droite)
CPS4EU: La vision de CPS4EU est d'encourager l'innovation qui maintiendra et renforcera le leadership européen dans les secteurs clés de l'économie en créant des synergies entre les PME, les grandes entreprises et les grands organismes de recherche opérant dans le secteur du CPS (Cyber Physical Systems). https://cps4eu.eu/

L’apprentissage par renforcement regroupe l’ensemble des méthodes d’apprentissage machine permettant de résoudre les problèmes de prise de décision séquentielle. Il se caractérise par un agent qui interagit de façon continue avec son environnement et qui apprend à maximiser la somme des récompenses qu’il reçoit. L’apprentissage par renforcement a été utilisé avec beaucoup de succès pour résoudre le problème de gestion de ressources, le développement d’agents intelligents pour les jeux de plateau, les jeux vidéo, ou encore la robotique.
Nous travaillons sur plusieurs axes de recherche qui vise à développer l’utilisation des algorithmes d’apprentissage par renforcement dans nos applications: apprendre des représentations efficaces pour les signaux de grande dimension comme l’image pour stabiliser le processus d’entrainement, développer des agents explicables et interprétables pour faciliter leur acceptation dans les applications critiques comme la conduite autonome, travailler la capacité de généralisation des agents et leur transfert des simulateurs vers le monde réel.
La réidentification automatique de personnes est une fonctionnalité clé pour les applications de vidéoprotection. Au cours des dernières années, les modèles utilisant l'apprentissage profond sont devenus la norme. Cependant, il a été démontré que les réseaux de neurones sont imparfaits face à des exemples antagonistes, c'est-à-dire des perturbations imperceptibles par l'homme. Ce problème a été largement étudié pour la tâche de classification d'images en ensembles dits fermés (mêmes classes durant l’entraînement et la phase de test). Cependant, il peut également apparaître dans le cas de tâches de recherche de données en ensembles dits ouverts (classes différentes entre l’entraînement et le test). En effet, des travaux récents ont montré que nous pouvons également générer des exemples antagonistes pour les systèmes d'apprentissage de métriques tels que ceux de la réidentification. Ces modèles sont donc vulnérables : face à des exemples antagonistes, ils ne reconnaissent pas correctement une personne, ce qui représente une faille de sécurité. Ces attaques sont d'autant plus dangereuses qu'elles sont impossibles à détecter pour un opérateur humain. Attaquer une métrique consiste à modifier les distances entre la caractéristique d'une image attaquée et celles des images de référence, appelées "guides".
Nous montrons que la faisabilité d'une attaque dépend de la disponibilité de tels guides. Ainsi, pour faire face à deux situations extrêmes de non-disponibilité et de disponibilité totale de guides, nous proposons deux nouvelles attaques [3] : l'attaque Self Metric (SMA) et l'attaque Furthest Negative (FNA). Cette dernière (cf. illustration du principe ci-dessus) surpasse l'état de l'art comme le montre le graphique ci-dessous (performance du modèle attaqué en fonction de la taille de la perturbation). De plus, pour défendre les modèles de réidentification et augmenter ainsi leur robustesse, nous proposons une extension efficace du protocole d'entraînement adversaire adapté à l'apprentissage de métriques [3].
Le code source est disponible sur notre github.
[1] Open Set Adversarial Examples. Zhedong Zheng et al. In arXiv:1809.02681
[2] Metric Attack and Defense for Person Re-identification. Bai S. et al. 2019. In arXiv:1901.10650
[3] Vulnerability of Person Re-Identification Models to Metric Adversarial Attacks, Bouniot Q., Audigier R. and Loesch A., Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) 2020
Sinkhorn Adversarial Training (SAT):
Défense contre les Attaques Antagonistes par Transport Optimal
Les méthodes les plus efficaces pour défendre les réseaux de neurones contre les attaques antagonistes s'entrainent sur des exemples antagonistes générés pour apprendre leur distribution. Les travaux précédents consistaient à aligner les représentations d'images originales et antagonistes à la manière d'une adaptation de domaine.
Dans ces travaux [4], l'analogie à l'adaptation de domaine est étendue puisque nous exploitons la théorie du transport optimal. Nous proposons d'utiliser une fonction de perte basée sur la divergence de Sinkhorn pour aligner ces distributions. Cela conduit à la méthode SAT (Sinkhorn Adversarial Training), une défense globalement plus robuste contre les attaques antagonistes que les méthodes de l'état de l'art.
Ensuite, nous proposons de quantifier plus précisément la robustesse d'un modèle aux attaques antagonistes sur une large gamme de tailles de perturbations en utilisant une métrique différente de l'état de l'art, l'AUAC (Area Under the Accuracy Curve).
Le code source est disponible sur notre github.
[4] Optimal Transport as a Defense Against Adversarial Attacks, Quentin Bouniot, Romaric Audigier, Angélique Loesch, The IEEE 25th International Conference on Pattern Recognition (ICPR'20), January 2021.