
Logiciels

PIXANO
Outil intelligent opensource d’annotation de données visuelles
LIMA
Analyseur linguistique (open source et propriétaire), plus de 60 langues

Datasets

DAHLIA : DAily Human Life Activity
DAHLIA est un dataset pour la recherche sur la reconnaissance d’activités de la vie quotidienne
MEL: Multimedia Entity Linking
Méthode pour fabriquer un corpus de désambiguïsation d’entités, utilisant les informations visualles et textuelles


CCIHP : Characterized Crowd Instance-level Human Parsing
CCIHP est un dataset pour la recherche sur la description fine de personnes à l’aide d’attributs sémantiques localisés et caractérisés. Il est constitué de 20 classes d’attributs et 20 classes de caractéristiques découpés en 3 catégories (taille, motif et couleur).
FALLMUD : FAscicle Lower Leg Muscle Ultrasound Dataset
FALLMUD est composé de 812 images échographiques des muscles de la jambe inférieure annotées avec des masques de faisceaux musculaire et des aponévroses.

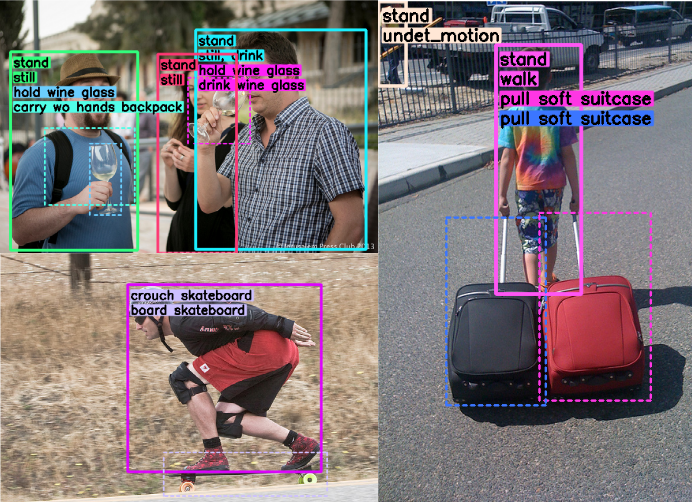
H²O: Human-to-Human-or-Object Interaction Dataset
H²O est un dataset image pour la détection d’interactions. H²O est annoté selon une nouvelle taxonomie de verbe d’interaction incluant à la fois les interactions entre personne et objet et les interactions entre personnes.
Base de données pour le suivi des joueurs de rugby à 7
Notre dataset est composé de trois extraits de 40 secondes de matchs du tournoi World Rugby 2021 à Dubai. Chaque extrait vidéo est annoté avec des données de suivi des joueurs.


Open-set object detection: towards unified problem formulation and benchmarking (ECCV Workshop 2024)
Nous fournissons des benchmarks unifiés (VOC-COCO et OpenImagesRoad) ainsi que les codes de nouvelles métriques d’évaluations pour l’Open-Set Object Detectin selon le papier ‘Open-set object detection: towards unified problem formulation and benchmarking (ECCV Workshop 2024)‘